Giovanni Yoko Kristianto
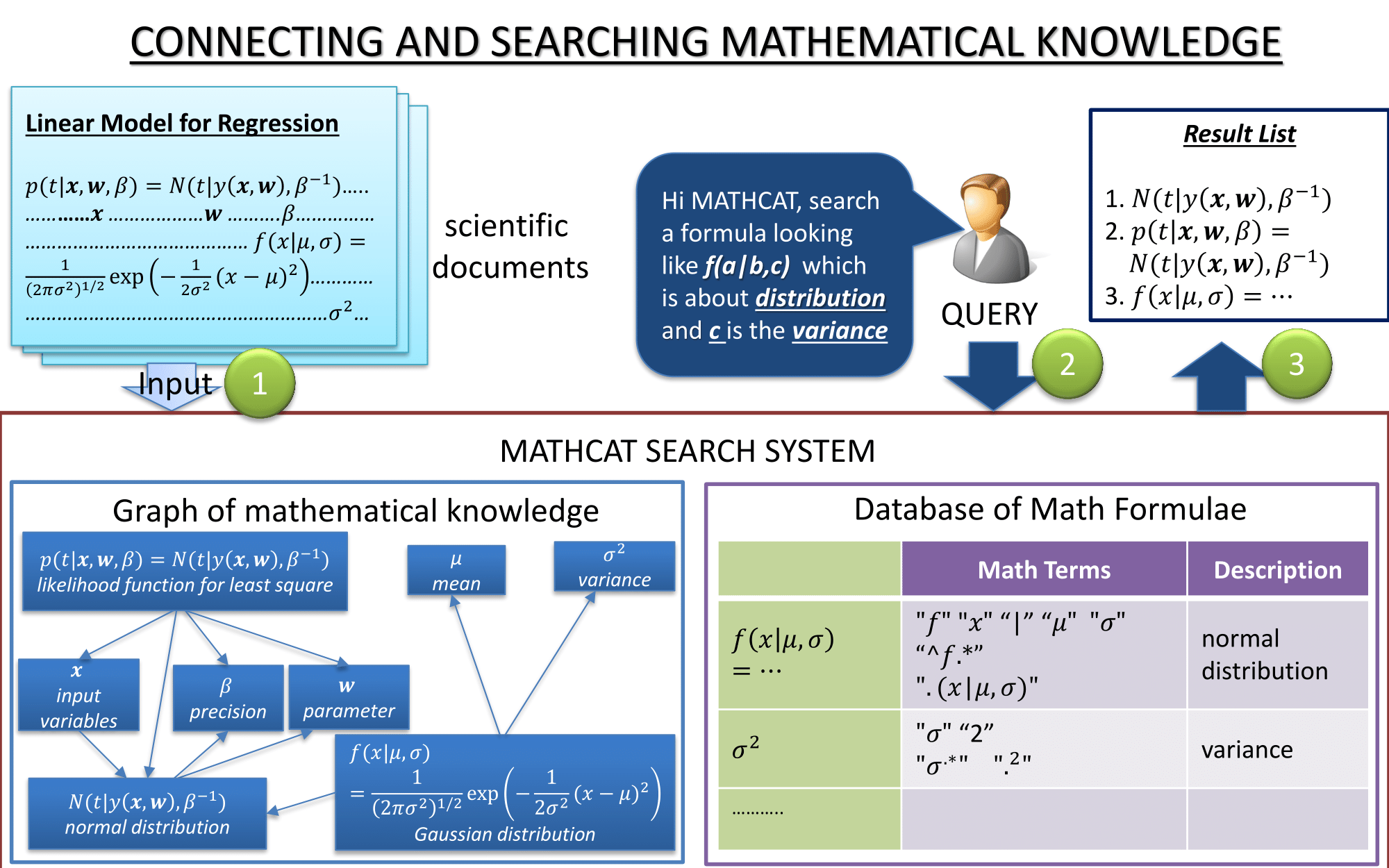
Mathematical formulae are commonly used by scientists to effectively
explain or define concepts. Therefore, mathematical formulae hold rich, and
often unambiguous, information.
The goal of this research is to create graph of mathematical knowledge by
connecting related mathematical formulae. The main challenge is when we
need to connect related mathematical formulae across documents.
Mathematical formulae with similar presentation may in fact represent
different concepts. Yet, formulae with very different presentation may
represent the same concept.
Once reliable graph of mathematical knowledge can be generated, we can
utilize it to support our current mathematical search system MATHCAT.
服部 一浩

山谷 彬人
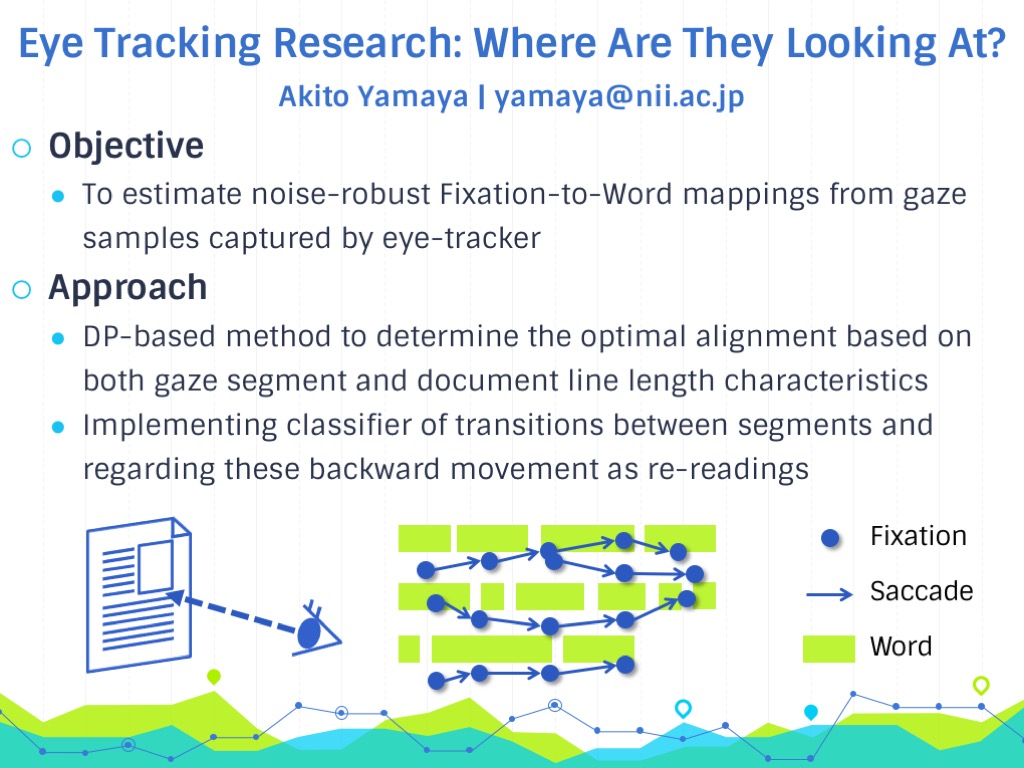
Eye movements made when reading text are considered to be important clues
for estimating both understanding and interest. To analyze gaze data
captured by the eye tracker with respect to a text, we need a noise-robust
mapping between a fixation point and a word in the text. In our research,
we propose a dynamic-programming–based method for effective
fixation-to-word mappings that can reduce the vertical displacement in gaze
location. The golden dataset is created using FixFix, our web-based manual
annotation tool. We first divide the gaze data into a number of sequential
reading segments, then attempt to find the best segment-to-line alignment.
To determine the best alignment, we select candidates for each segment, and
calculate the cost based on the length characteristics of both the segment
and document lines. We compare our method with the na ̈ıve mapping method,
and show that it is capable of producing more accurate fixation-to-word
mappings.
城戸 祐亮
菅原 朔

橋本 捷斗
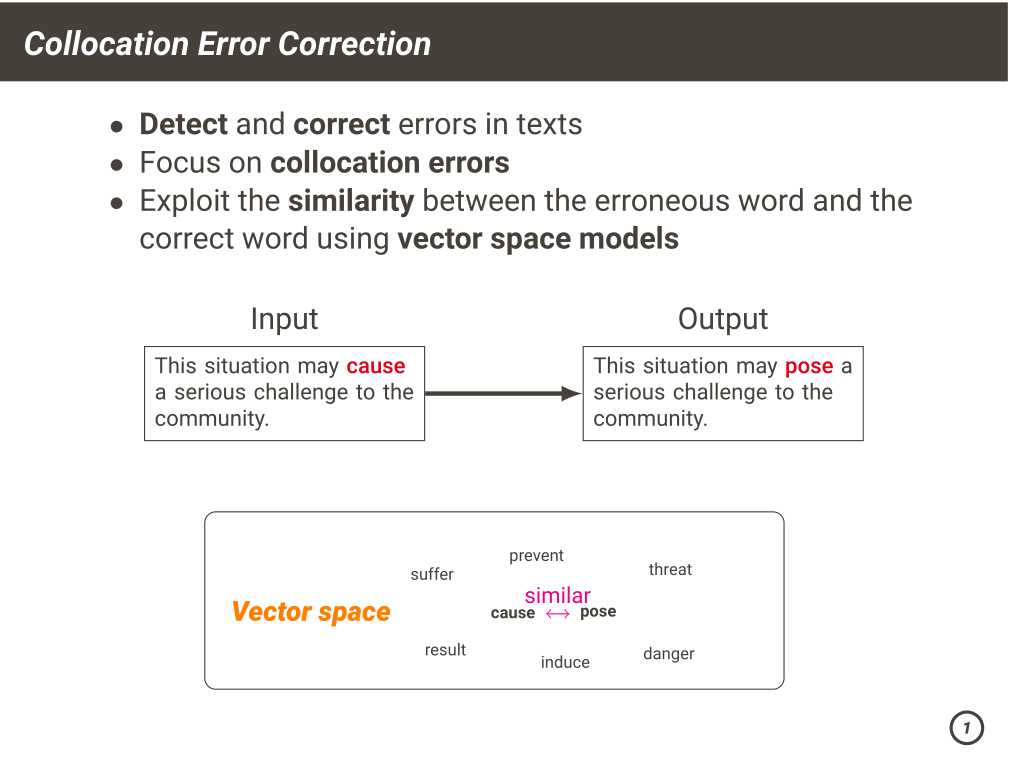
Grammatical error correction (GEC) has been intensively studied for English.
In our research, we focus on collocation errors and use a approach using
vector space models. Collocation errors are word combinations that are
syntactically correct but unidiomatic. The words constituting collocation errors
tend to be similar to the correct ones. We exploit the similarity between words to find the best candidates.
Christopher Norman
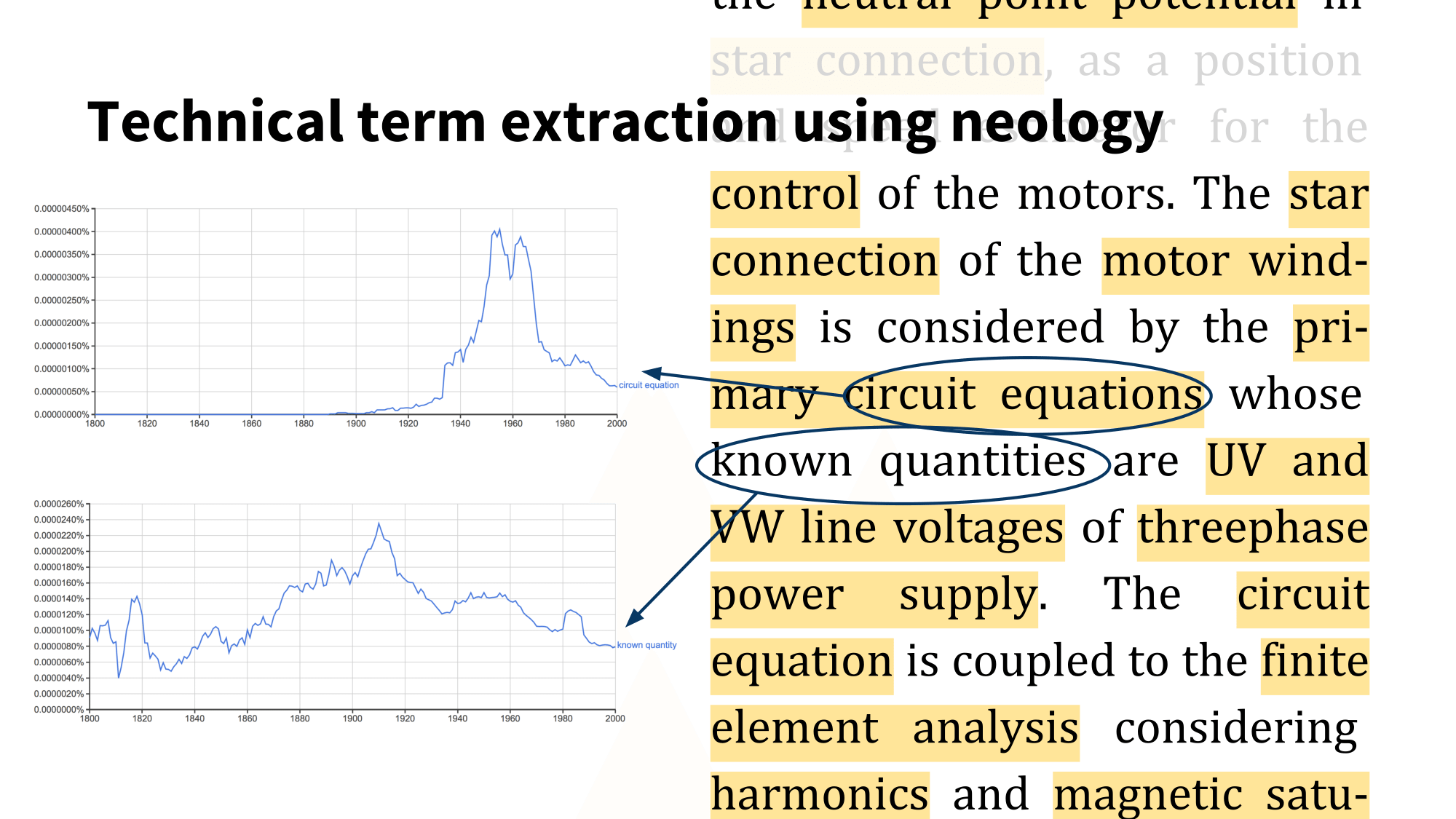
I currently work on automatic methods for detecting technical terms in
technical and scientific articles. Detecting technical terms is useful
because these are generally the main bearers of content in a text.
Consequently, extracting the technical terms allows us to get a
summary of the content of a text or sentence, a sense of what it is about.
This is useful in several situations, such as information retrieval,
document summary generation, or keyphrase
extraction, and can also be used for instance in the automatic generation
of technical dictionaries.
My main interest is in using machine learning methods to detect technical
terms based on their novelty, i.e. how recently the phrase was first used,
and when and how the phrase started to gain traction in the literature.