Felix Hamborg
News aggregators are able to cope with the large amount of news that is published nowadays. Therefore, they gather, aggregate, and summarize news articles from many news website. However, they focus on the presentation of important, common information, but do not reveal different perspectives of related articles on a topic. For instance, in an international conflict the involved parties often have differing, sometimes even contrary, perspectives on the same events. Thus, news aggregators suffer from media bias, a phenomenon that describes differences in news such as in their content or tone.
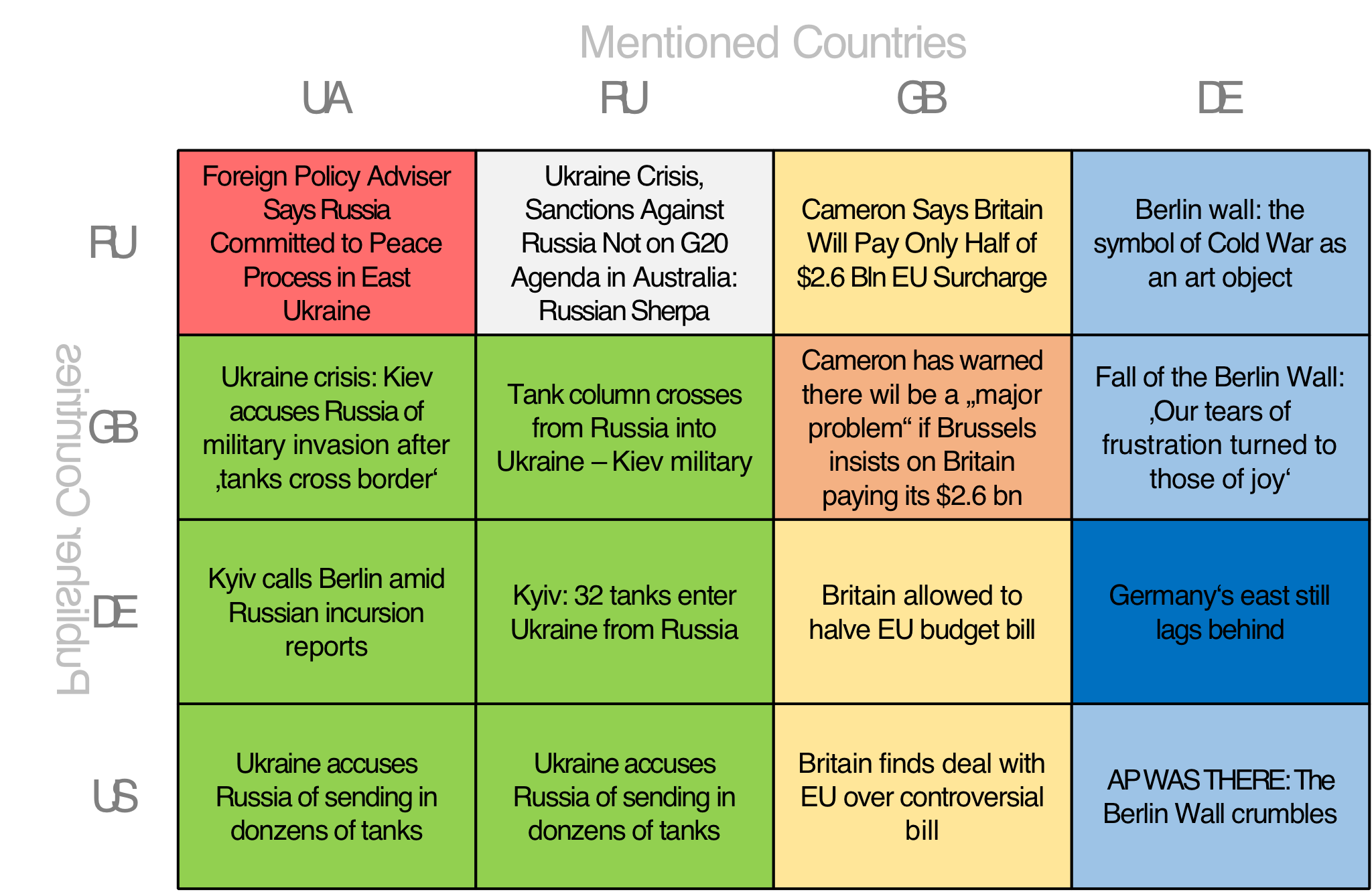
My internship focuses on the development of NewsBird, a news aggregator that not only shows common but also differing information. NewsBird aims to reduce the effects of media bias and helps users to gain a broad and diverse news understanding by presenting them various, possibly biased, news perspectives on the same topic. Currently NewsBird uses a matrix (as shown in the figure) to organize news articles so that the resulting cells achieve a high expected information diversity.
Hayato Hashimoto
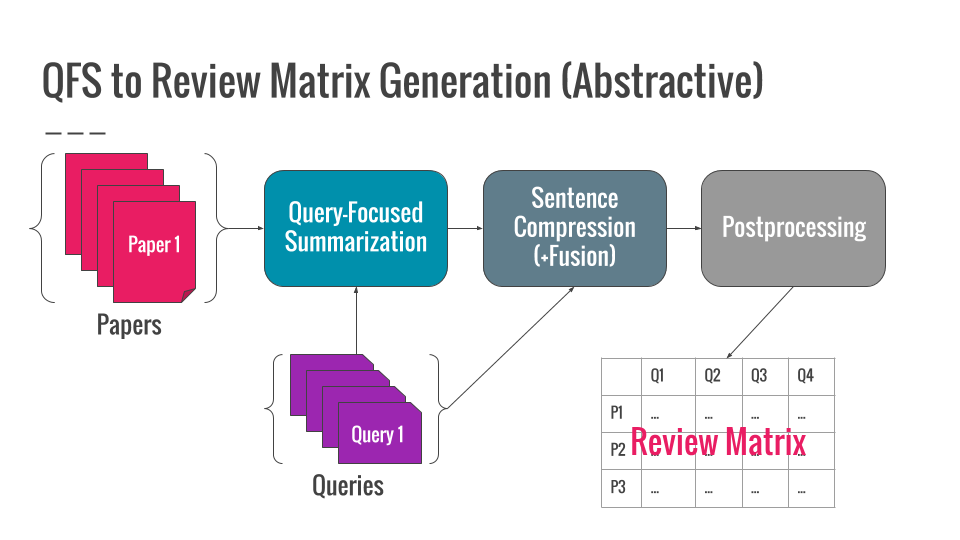
A review matrix is a table that describes the differences between documents based on certain aspects. Our goal is to automatically generate review matrices for scientific papers. Considering that each item in a review matrix can be viewed as a brief summary of the corresponding document on some aspect, we utilize techniques for summarization for review matrix generation.
Jacqueline Hofmann
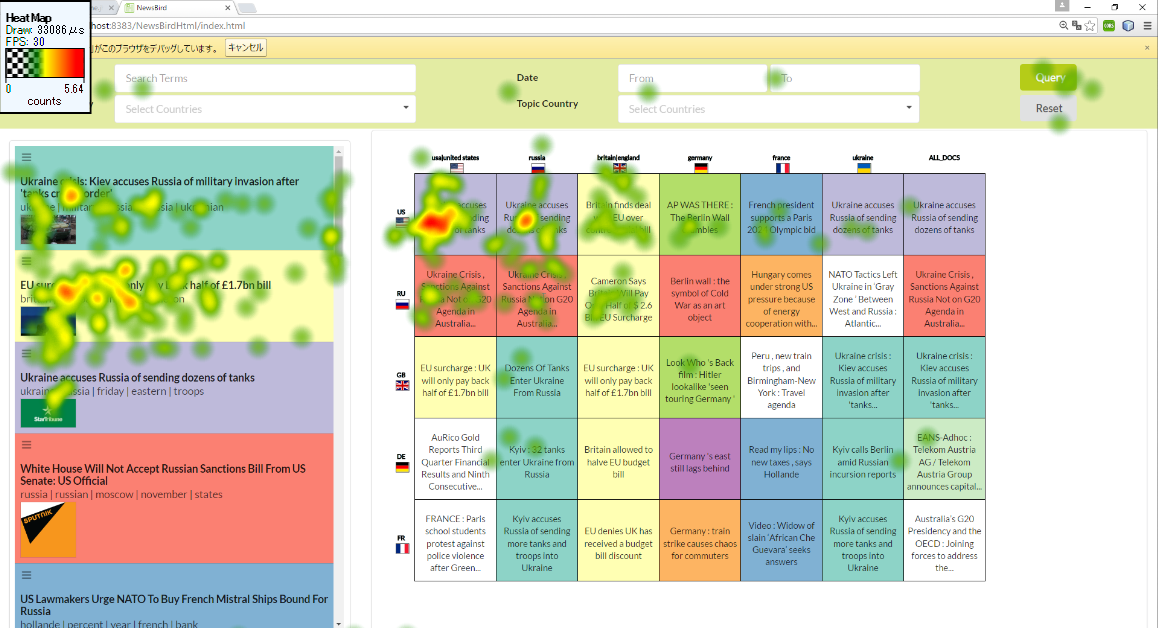
In collaboration with Felix Hamborg, my actual internship activity focuses on the novel news aggregator Newsbird.
To broaden the news perspective for the normal web user, different uses cases with varying visualizations can be applied.
We iteratively design, develop and evaluate the increments of Newsbird with commonly known Human-Computer-Interaction methods like
Heuristic Evaluation, User Studies and Case Studies with the use of Eye tracking.
Kenichi Iwatsuki

Now I’m interested in assistance by means of computational linguistics in non-native speakers of English writing a scholarly paper in English.
The aim of my research is to automatically complete sentences when one is writing and revise incorrect expressions used in an article.
I’m trying to find effective ways of searching corpora of scientific papers for phrases consisting of a complete sentence and exploiting context of a paper.
Yusuke Kido
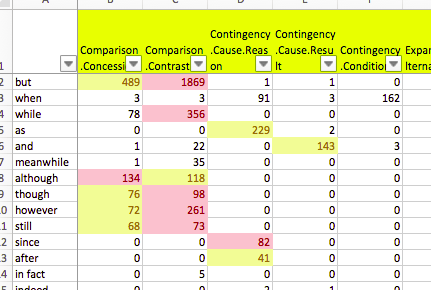
I am currently working on discourse analysis.
Natural language texts can be viewed as a series of discourse relations, which connect two (typically adjacent) pieces of text, supported by the function of discourse connectives (e.g. “but”, “therefore”).
My aim is to assist scientists and/or students on writing scientific papers, by presenting information gathered through discourse analysis as they type.
This is an interdisciplinary study over computational linguistics and human-computer interaction.
Giovanni Yoko Kristiano
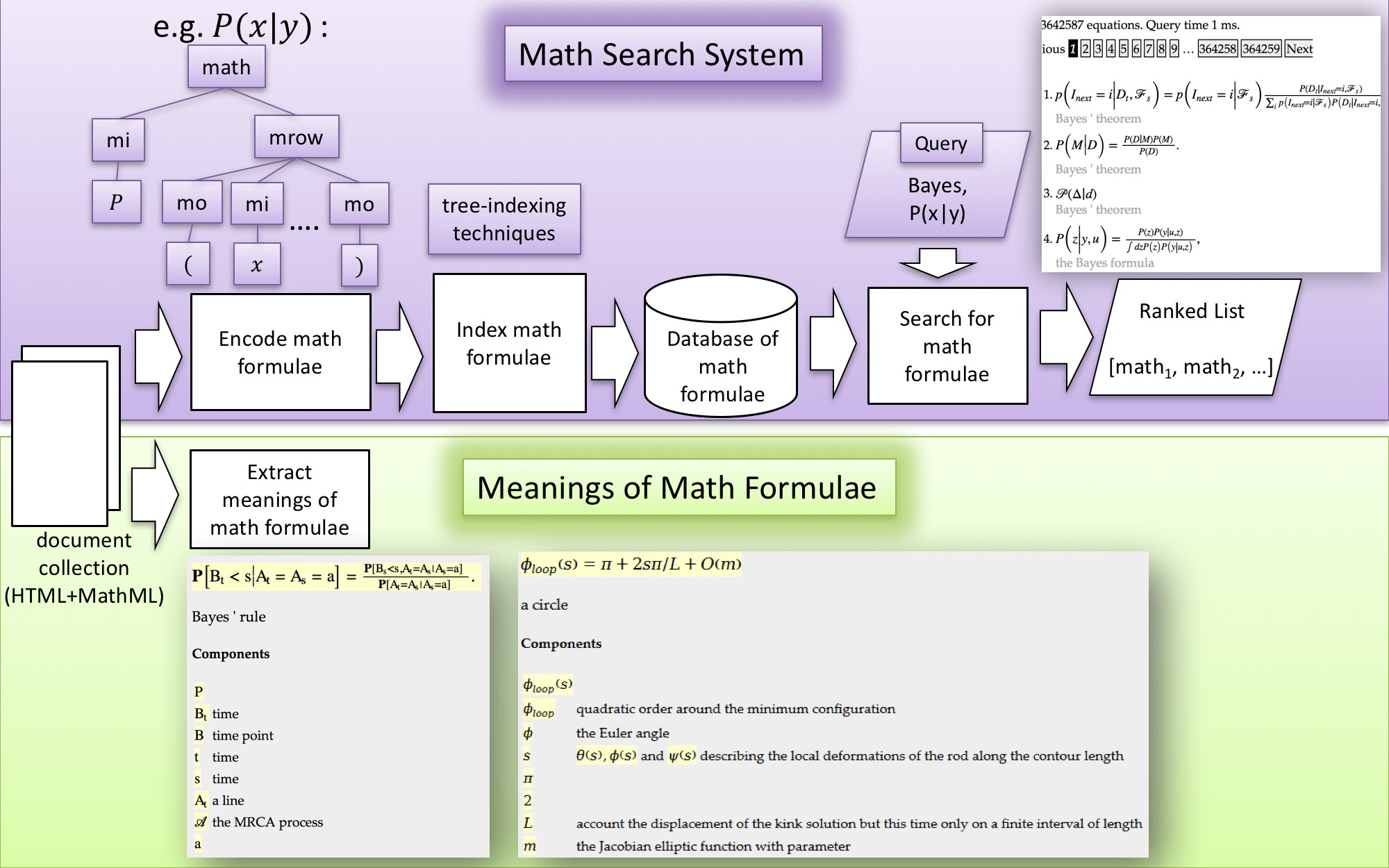
I am working on the development of mathematical information access system.
This purpose of this system is to enable students or researchers to efficiently access math information in scientific documents.
Up to now, this system consists of two modules:
(a) math search system and
(b) extraction of textual descriptions of math formulae.
Ongoing and possible topics in this area include, but are not !!limited to: (1) improving the current search system using heuristic or machine learning (learning to rank) approaches, (2) finding related and semantically similar math expressions across documents, and (3) generating concept graphs from dependency relationships between math formulae.
Thomas Perianin
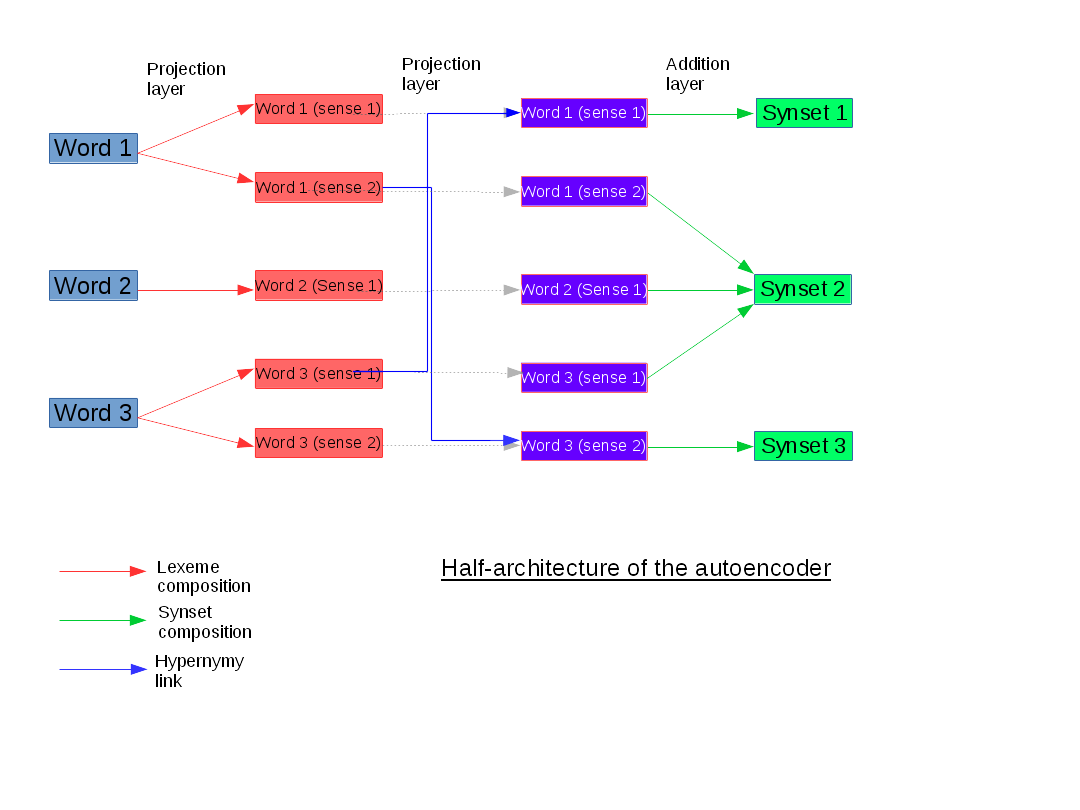
My current work is about distributed representations.
We exploit semantic relations, in particular the hypernymy relation present in the WordNet corpus, to extend the autoencoder model proposed by Rothe et al. (2015) and to obtain distributed representations of synsets and lexemes.
We use the relations to define the topology of the neural network and try to understand if it has an impact on the quality of the learned embeddings.
For this purpose, we use the task of word-sense disambiguation.
Hajime Senuma
Morphological and syntatic analyses are fundamental yet challenging areas in natural language processing, mainly due to the diversity of linguistic characters. We address the problem by considering three wide topics. First, we investigate appropriate linguistic models with theoretical tools such as computational complexity, paradigm learning, and universal dependencies. Second, we employ several distinct machine learning techniques to overcome resource scarceness, notably active learning and L1 feature selection. Finally, we handle infomation by such as L1 optimization and succinct data structures.
Saku Sugawara
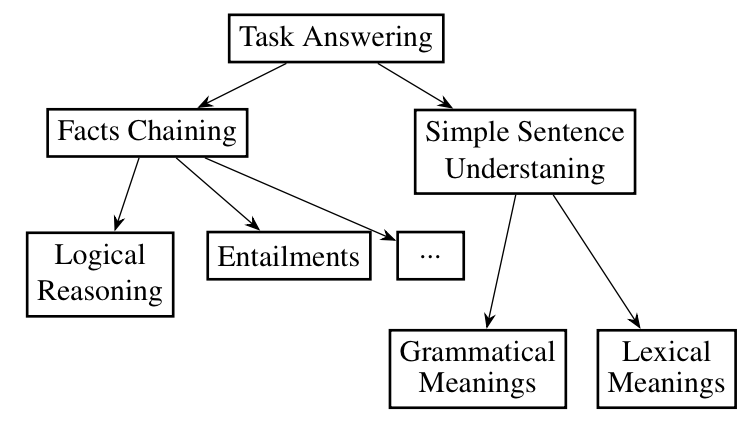
We propose a new design methodology for comprehensive achievement test for natural language understanding (NLU) systems. We first investigate the expected NLU skills of several existing NLU tasks and enumerate all the grammatical elements and reasoning types used in these tasks. Based on the analysis, we expand the concept of “toy tasks” proposed by Weston et. al. and formulate “unit tests” where each test is defined as a QA-style task consisting of contextual statements and a query using only a specific grammatical element and a reasoning type. We also describe the prerequisite properties of the semantic representations needed for the unit tests, and discuss the advantages and disadvantages of commonly used representations. Then, we focus on Abstract Meaning Representation (AMR) and demonstrate how the AMR can be extended for the unit test. (For more details, see our papers in JSAI2016 (to be appeared) or NLP2016 (http://www.anlp.jp/proceedings/annual_meeting/2016/pdf_dir/P4-6.pdf))
Joeran Beel
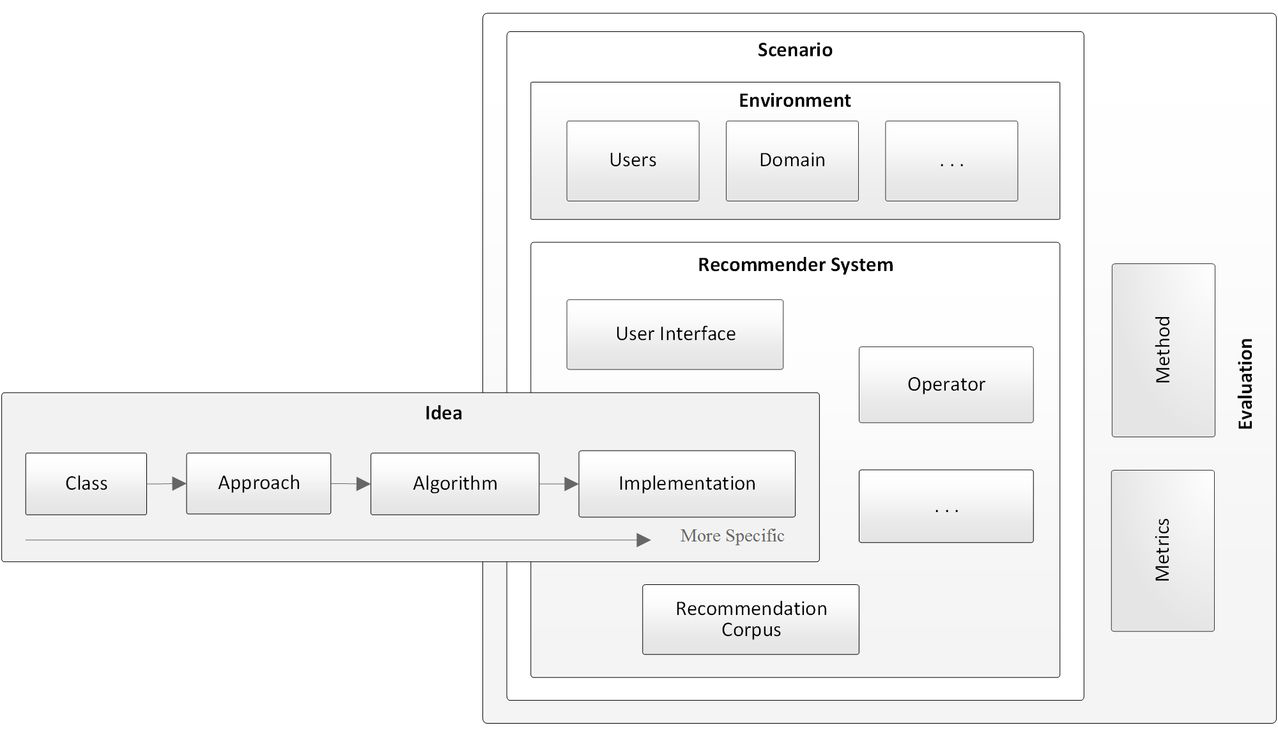
Reproducibility is the cornerstone of science. However, in the recommender-system community, reproducibility is widely neglected, and it remains unknown, which factors affect reproducibility. Consequently, there are many instances of unreproducible research. My research goal is to explore, which factors are responsible for (non-) reproducibility in recommender-systems research. To achieve this goal, I will implement different recommendation approaches, vary the recommendation scenarios, and evaluate the approaches’ effectiveness with different evaluation methods. These variations in recommendation approaches, scenarios, and evaluation methods will allow me to identify which variations affected the recommendation effectiveness, to what extent, and hence affect the reproducibility of recommender-systems research.