情報技術の発達によって、膨大な量の言語テキストを計算機で扱うことが可能になりました。しかし、必要な情報が、必要とするそのままの形でテキスト中に書かれているとは限りません。テキスト中に埋め込まれた知識は、それを読む人間の理解を介して、はじめて知識として利用可能な形になります。このように知識を変換したり組み合わせたりして活用する人間の知能の本質的な働きを捉えらることは、人工知能の大きなチャレンジとなっています。本プロジェクトでは、汎化や統合、推論などの操作により生み出される広がりを持つ知識空間の探索という、より本質的な課題に挑戦するため、計算機による言語解析を用いた知識の獲得、および、獲得した知識の活用に関する研究を進めています。
断片化する知識をつなぐ:テキストのリンキング技術とその応用
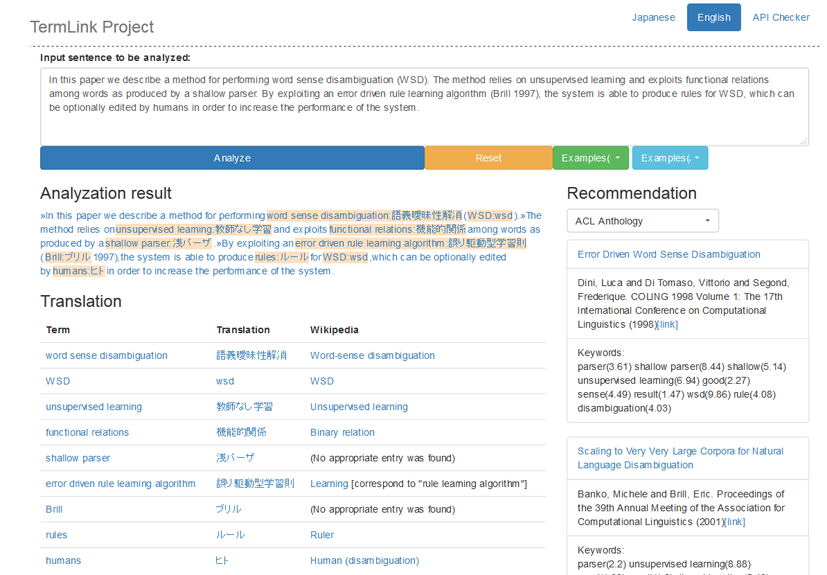
TermLink server demo
情報社会において日々生産・蓄積される膨大な量のコンテンツを活用するために、AIによる知識処理が切実に求められています。文章から知識を自動獲得する言語処理技術はその中核となるもので、中でも文章中の概念や事物の名前を外部知識に結びつける「エンティティ・リンキング」は、知識獲得に必須の技術として近年注目を集めています。しかし、現在のリンキング・システムの大半は人物名などの固有表現を想定するもので、知識の体系化に役立つ抽象的な概念は対象となっていません。そこで本プロジェクトでは、個々のドメインを特徴付ける「専門用語」に焦点をあて、専門用語を外部知識源に結びつけるための用語正規化、辞書構築、用語翻訳、語義あいまい性解消技術の研究を進めています。本研究ではリンキングによる知識処理の一例として、科学技術文書を対象とするリンキングサーバを実装するとともに、それを利用して日本語から英語への文献推薦やウィキペディア記事へのリンク抽出を行うデモシステムを構築しています。リンキングにより同定された概念は、情報獲得や知識推論の基本単位となることから、言語や分野を横断する知識発見や知識ベースどうしの統合などへの応用が期待されます。
論文の構造に沿った関連情報の推薦と閲覧支援システム
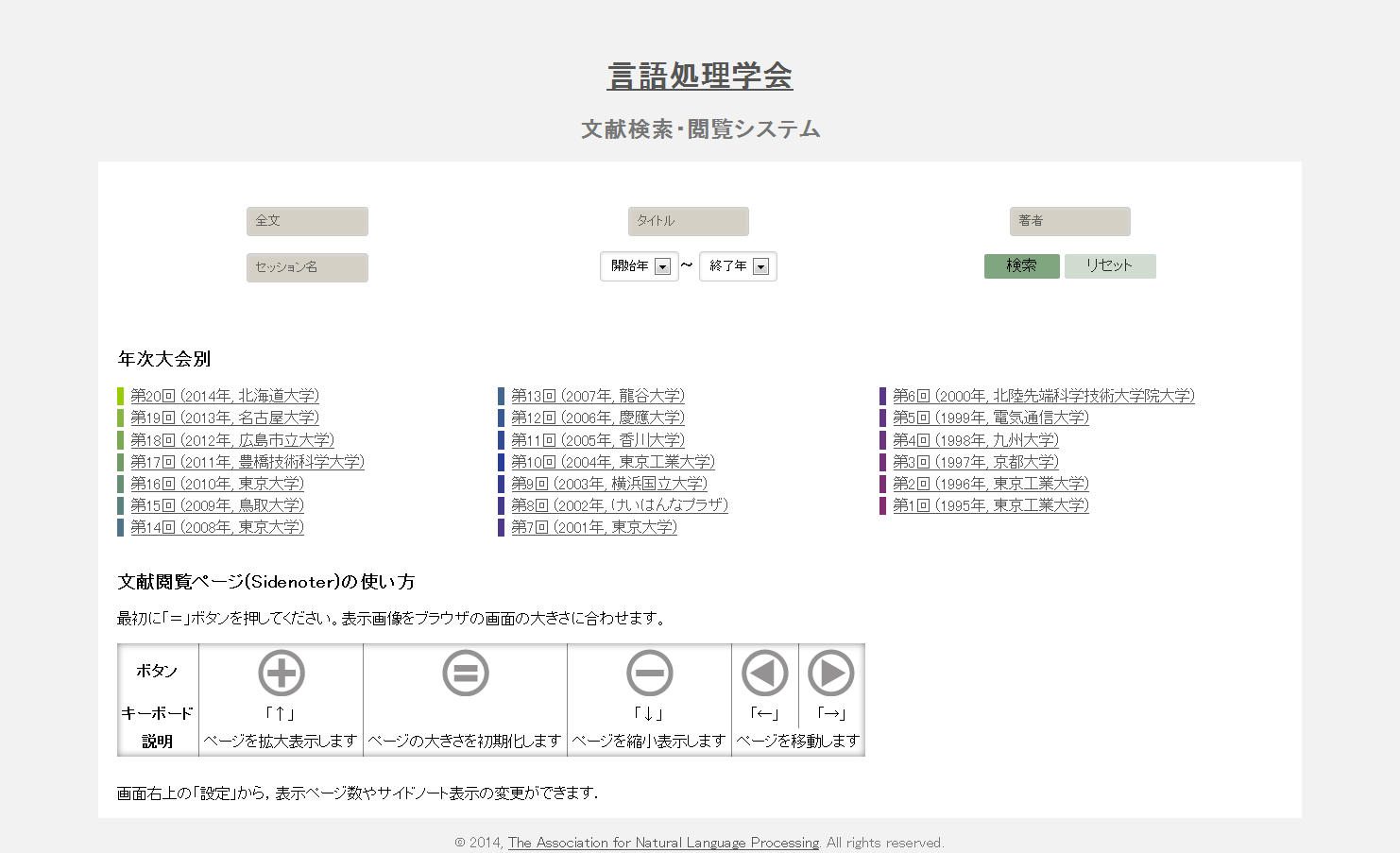
SideNoter demo site.
文書のセクションや段落などの論理構造に沿って、参考になる関連情報や知識ベース上の記事を推薦する文書閲覧支援の研究に取り組んでいます。特に、論文を対象とする「注釈付きPDF閲覧システムSideNoter」の開発・運用を、NIIの阿辺川武氏と協力して進めています。SideNoterは、推薦情報を注釈としてページの横に自動表示するもので、現在は、言語処理学会が公開している言語処理学会年次大会予稿集アーカイブを使ったデモサイトを立ち上げています。SideNoterの実現には、PDF文書の構造解析、用語リンキング、引用文献の同定、言語横断論文推薦など多様な技術が必要で、これらを含む論文の論理・意味構造解析手法の実証基盤としてSideNoterの活用が期待されます。(共同研究者:阿辺川武、相良毅)
構造化された文書からの自然言語文の抽出
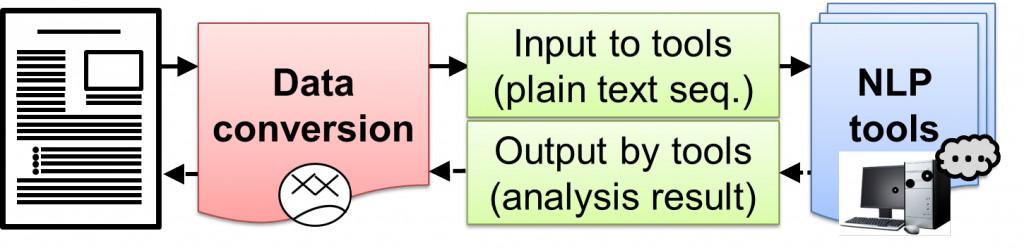
Converting XML document into plain text based on tag classification
自然言語処理を行うためのツールは、その入力として「文」を前提とするものが殆どですが、実際に解析対象となる文書の多くには、見出しや注釈など様々な構造情報がテキスト中に埋め込まれていて、そのままでは既存の自然言語ツールを適用することができません。本プロジェクトでは、「構造化されたテキストを含む実世界の文書を、手持ちの自然言語処理 (NLP) ツールで解析したい」という目的を支援するための枠組を提案し、PlaneTextと呼ぶ変換ツールを実装しました。現在のバージョンでは、XML タグで囲まれたテキストを NLP ツールに直接入力できるような文に変換することができます。このような取り組みによって、文書から抽出される「文」の質が高くなるとともに、構文解析等の効率も高めることができます。(原忠義、Goran Topić)
多様な観点から関連論文を推薦するオススメ論文推薦
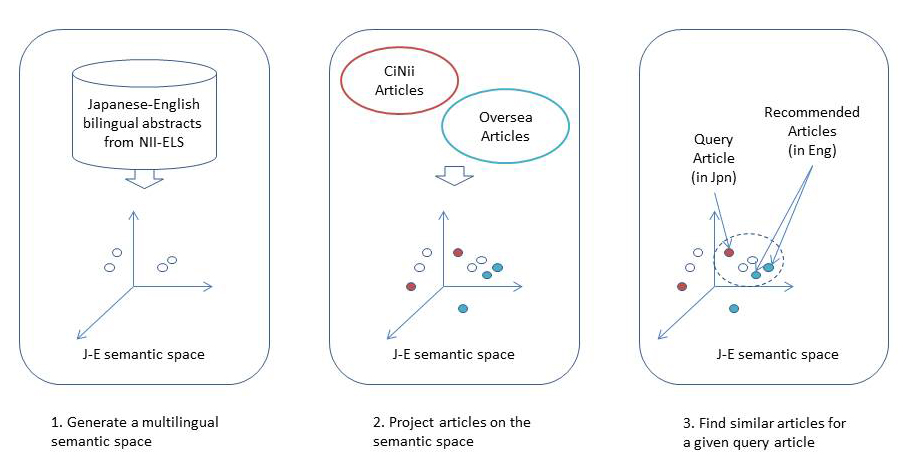
Cross-lingual scientific paper recommendation using LDA
本研究では、「人気度」「異分野性」などの多様な視点による論文検索を可能にする推薦システムを構築しました。このシステムでは、与えらえた論文に関連する論文を、複数のレコメンダが異なる視点に基づきランキングして利用者に提示します。(1)利用者が過去に執筆した論文からキーワードを抽出して、それを利用して関連の高い論文を優先的に推薦するパーソナライズ機能、(2)日本語論文の検索結果から国内・海外の最新論文を推薦する言語横断推薦機能、(3)論文中で使われている専門用語について論文の目的であるか手段であるかを分類して提示する意味役割付与機能、(4)分野間の距離を計算して意外性の高い論文を優先するセレンディピティ推薦など、多くの先進的な機能を試行的に実装しました。プロジェクトは2012年に終了しましたが、その経験は継続プロジェクトに引き継がれています。(共同研究者:高須淳宏、内山清子、難波英嗣、相良毅)
アカデミックリンケージ:書誌・著者同定によるデータ統合
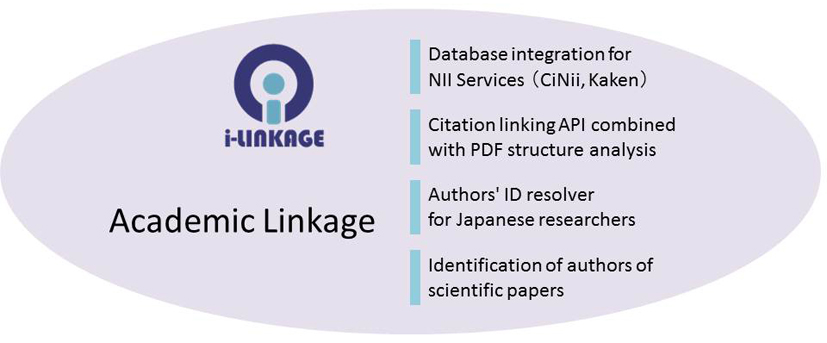
Information linkage engine for advance academic infrastructure.
論文データベースや図書カタログ上の書誌情報と、論文本文やウェブから抽出される引用文字列とを対応付けるための高速な情報リンケージ技術の開発に取り組み、サフィックスアレイと機械学習を用いた高速な書誌同定エンジン i-linkageを開発しました。また書誌同定を利用して、数千万人規模の論文著者を名寄せする研究者同定システムを開発しました。このような手法は学術情報基盤の高度化に欠かすことができないコア技術で、その重要性は広く認識されています。開発したエンジンは現在も、NIIサービスや後継プロジェクトでの論文や著者の同定に活用されています。