深層学習を前提とする今日の言語理解システムでは、システム設計の中心になるのは、データ収集や評価基準を含めた言語理解タスクのデザインです。 そこで、読解タスクや対話タスクの分析や設計を通して、言語理解に求められるスキルを測定したり、訓練に必要となる事例を収集したりする手法を研究します。
Evaluation Methodology for Machine Reading Comprehension Task: Prerequisite Skills and Readability
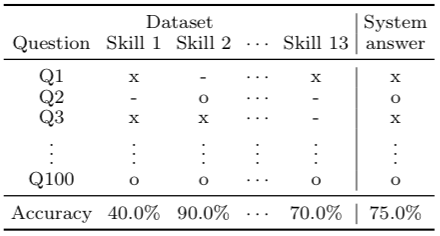
自然言語処理の目標のひとつは、言語が理解できるエージェントを作ることです。言語理解能力を測定する手段として読解タスク (reading comprehension task) があり、国語の文章題のように文書を与えて質問に答えさせます。ここで問題になるのは、この読解タスクに用いられる質問の性質です。「その問いがどのような能力を要求しているのか」がわからなければ、テストしたエージェントが何が得意か・不得意かを知ることができません。しかし多くのタスクではこういった分析指標がなく、エラー分析が困難になっていました。本研究では、「読解に要求される能力」と「文章の読みやすさ」という2つの指標を定義し、既存の6つのデータセットを分析しました。また、両指標の相関関係も調査しました。結果として、文章の読みやすさは問題の難易度に直接は影響しておらず、「文章が読みやすくても問題が難しい」ようなデータセットを作ることができることがわかりました。 (Sugawara et al.; Links [1] [2])
Improving the Robustness of QA Models to Challenge Sets with Variational Question-Answer Pair Generation
読解のための質問応答モデルは訓練時と同じ分布のテストセット(分布内テストセット)では人間と同程度の精度を達成することができます。
しかし、訓練時と異なる分布のテストセット(チャレンジセット)にはうまく汎化することができないことがわかっています。
既存のデータ拡張手法はチャレンジセットと同じ分布からサンプリングされたデータを用いてこの問題を解決しています。
ところがこのような手法はチャレンジセットの分布が訓練時に既知であるという仮定に基づいており、未知のチャレンジセットへの適用が困難だと考えられます。
そこで本研究では質問回答ペア生成によってこの問題を解決することを目指します。
特に多様性を重視した質問回答ペア生成によって質問応答モデルの頑健性を向上できるのではないかという仮説を立てました。
本研究では単一の文章から多様な質問回答ペアを生成できる変分質問回答ペア生成を提案します。
実験において、提案手法は分布内テストセットだけでなく12のチャレンジセットで精度を向上できることを確認しました。
(Shinoda et al.; Link: https://arxiv.org/abs/2004.03238)
A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps

A multi-hop question answering (QA) dataset aims to test reasoning and inference skills by requiring a model to read multiple paragraphs to answer a given question. However, current datasets do not provide a complete explanation for the reasoning process from the question to the answer. Further, previous studies revealed that many examples in existing multi-hop datasets do not require multi-hop reasoning to answer a question. In this study, we present a new multihop QA dataset, called 2WikiMultiHopQA, which uses structured and unstructured data. In our dataset, we introduce the evidence information containing a reasoning path for multi-hop questions. The evidence information has two benefits: (i) providing a comprehensive explanation for predictions and (ii) evaluating the reasoning skills of a model. We carefully design a pipeline and a set of templates when generating a question–answer pair that guarantees the multi-hop steps and the quality of the questions. We also exploit the structured format in Wikidata and use logical rules to create questions that are natural but still require multi-hop reasoning. Through experiments, we demonstrate that our dataset is challenging for multi-hop models and it ensures that multi-hop reasoning is required. (Ho et al., ([Link])