What is emphasized in system design in today’s language comprehensions systems underpinning deep learning is the design of language comprehension tasks including data collection and evaluation criteria. We study methods to measure skills that are demanded for language understanding and to collect cases required for training through the analysis and design of machine reading comprehension and natural language communication.
Evaluation Methodology for Machine Reading Comprehension Task: Prerequisite Skills and Readability
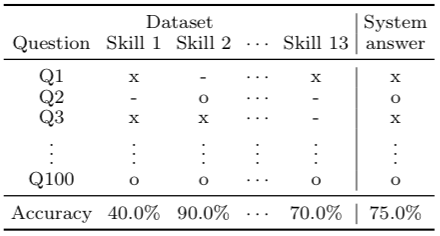
A major goal of natural language processing (NLP) is to develop agents that can understand natural language. Such an ability can be tested with a reading comprehension (RC) task that requires the agent to read open-domain documents and answer questions about them. In this situation, knowing the quality of reading comprehension (RC) datasets is important for the development of language understanding agents in order to identify what the agents can and cannot understand in the evaluation. However, a detailed error analysis is difficult due to the lack of metrics in recent datasets. In this study, we adopted two classes of metrics for evaluating RC datasets: prerequisite skills and readability. We applied these classes to six existing datasets, including MCTest and SQuAD, and demonstrated the characteristics of the datasets according to each metric and the correlation between the two classes. Our dataset analysis suggested that the readability of RC datasets does not directly affect the question difficulty and that it is possible to create an RC dataset that is easy-to-read but difficult-to-answer. (Sugawara et al.; Links [1] [2])
Improving the Robustness of QA Models to Challenge Sets with Variational Question-Answer Pair Generation
Question answering (QA) models for reading comprehension have achieved human-level accuracy on in-distribution test sets.
However, they have been demonstrated to lack robustness to challenge sets, whose distribution is different from that of training sets.
Existing data augmentation methods mitigate this problem by simply augmenting training sets with synthetic examples sampled from the same distribution as the challenge sets.
However, these methods assume that the distribution of a challenge set is known a priori, making them less applicable to unseen challenge sets.
In this study, we focus on question-answer pair generation (QAG) to mitigate this problem.
While most existing QAG methods aim to improve the quality of synthetic examples,
we conjecture that diversity-promoting QAG can mitigate the sparsity of training sets and lead to better robustness.
We present a variational QAG model that generates multiple diverse QA pairs from a paragraph.
Our experiments show that our method can improve the accuracy of 12 challenge sets, as well as the in-distribution accuracy.
(Shinoda et al.; Link: https://arxiv.org/abs/2004.03238)
A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps

A multi-hop question answering (QA) dataset aims to test reasoning and inference skills by requiring a model to read multiple paragraphs to answer a given question. However, current datasets do not provide a complete explanation for the reasoning process from the question to the answer. Further, previous studies revealed that many examples in existing multi-hop datasets do not require multi-hop reasoning to answer a question. In this study, we present a new multihop QA dataset, called 2WikiMultiHopQA, which uses structured and unstructured data. In our dataset, we introduce the evidence information containing a reasoning path for multi-hop questions. The evidence information has two benefits: (i) providing a comprehensive explanation for predictions and (ii) evaluating the reasoning skills of a model. We carefully design a pipeline and a set of templates when generating a question–answer pair that guarantees the multi-hop steps and the quality of the questions. We also exploit the structured format in Wikidata and use logical rules to create questions that are natural but still require multi-hop reasoning. Through experiments, we demonstrate that our dataset is challenging for multi-hop models and it ensures that multi-hop reasoning is required. (Ho et al., ([Link])