For humans and computers to communicate via natural language text, it is necessary that the understanding (interpretation) of the given texts be shared. In this research, we tackle the issues of dialogue system and language grounding.
Evaluating Quality of a Dialogue Response
Decomposition the structure ofa response quality
Evaluating natural language is a challenging task. Without a proper assessment of a text’s quality, it is difficult to determine which models can produce a better generation. In this research, we focus on techniques to enhance the evaluation of NLG.
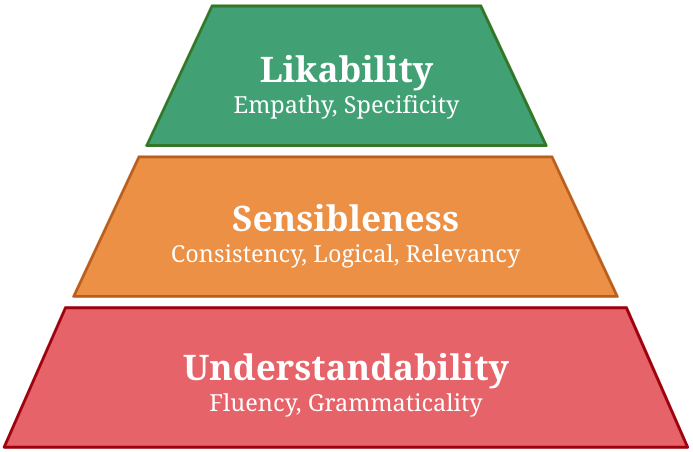
Many automatic evaluation metrics have been proposed to score the overall quality of a response in open-domain dialogue. Generally, the overall quality is comprised of various aspects, such as relevancy, specificity, and empathy, and the importance of each aspect differs according to the task. For instance, specificity is mandatory in a food-ordering dialogue task, whereas fluency is preferred in a language-teaching dialogue system. However, existing metrics are not designed to cope with such flexibility. For example, BLEU score fundamentally relies only on word overlapping, whereas BERTScore relies on semantic similarity between reference and candidate response. Thus, they are not guaranteed to capture the required aspects, i.e., specificity. To design a metric that is flexible to a task, we first propose making these qualities manageable by grouping them into three groups: understandability, sensibleness, and likability, where likability is a combination of qualities that are essential for a task. We also propose a simple method to composite metrics of each aspect to obtain a single metric called USL-H, which stands for Understandability, Sensibleness, and Likability in Hierarchy. We demonstrated that USL-H score achieves good correlations with human judgment and maintains its configurability towards different aspects and metrics. [ Vitou Phy et al.: COLING-2020 , https://github.com/vitouphy/usl_dialogue_metric ]
Maintaining Common Ground in Dynamic Environments
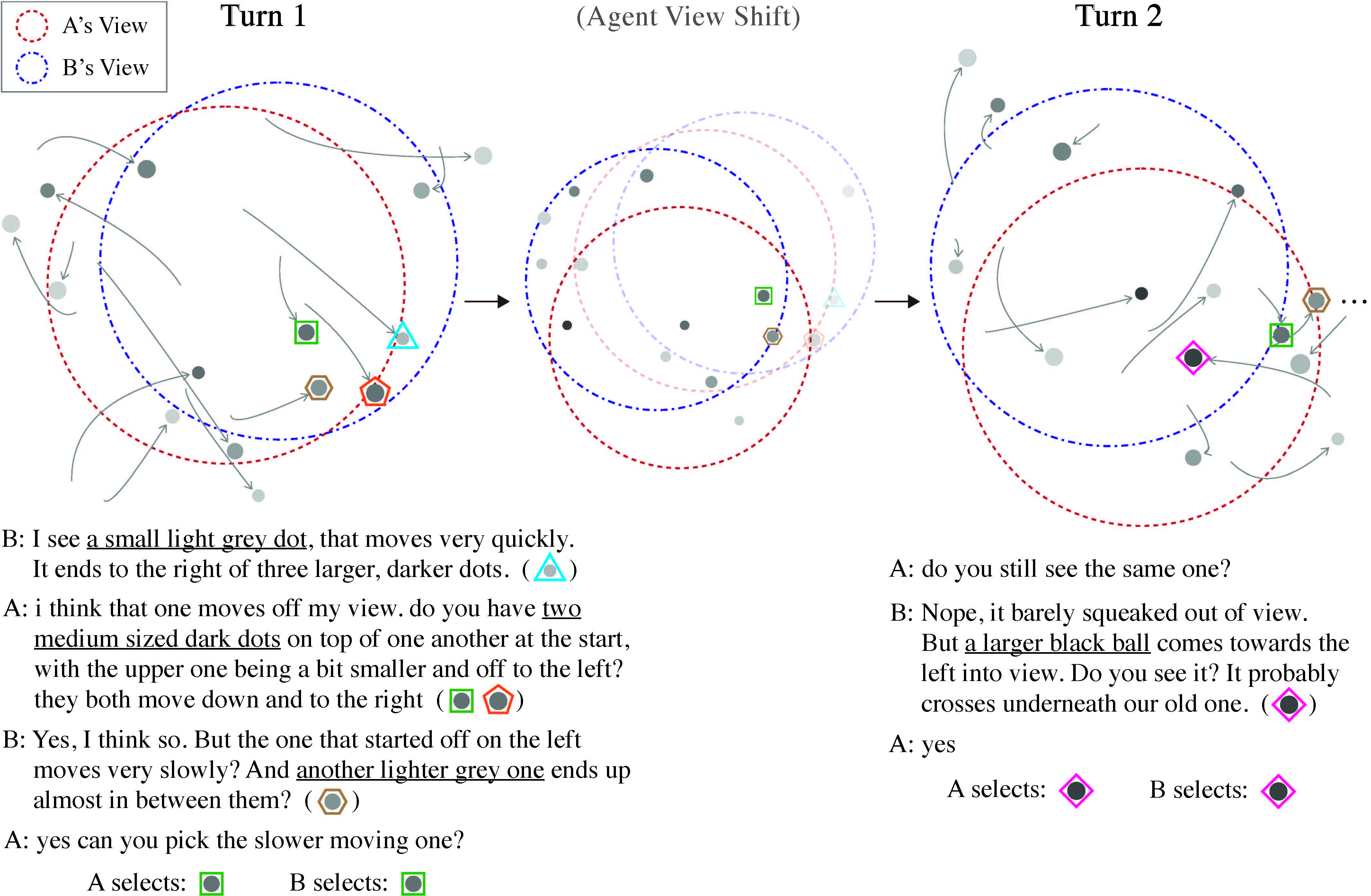
Common grounding is the process of creating and maintaining mutual understandings, which is a critical aspect of sophisticated human communication. While various task settings have been proposed in existing literature, they mostly focus on creating common ground under static context and ignore the aspect of maintaining them overtime under dynamic context. In this work, we propose a novel task setting to study the ability of both creating and maintaining common ground in dynamic environments. Based on our minimal task formulation, we collected a large-scale dataset of 5,617 dialogues to enable fine-grained evaluation and analysis of various dialogue systems. Through our dataset analyses, we highlight novel challenges introduced in our setting, such as the usage of complex spatio-temporal expressions to create and maintain common ground. Finally, we conduct extensive experiments to assess the capabilities of our baseline dialogue system and discuss future prospects of our research.(Udagawa and Aizawa: TACL 2021, dataset)
Creating Common Ground under Continuous and Partially-Observable Context
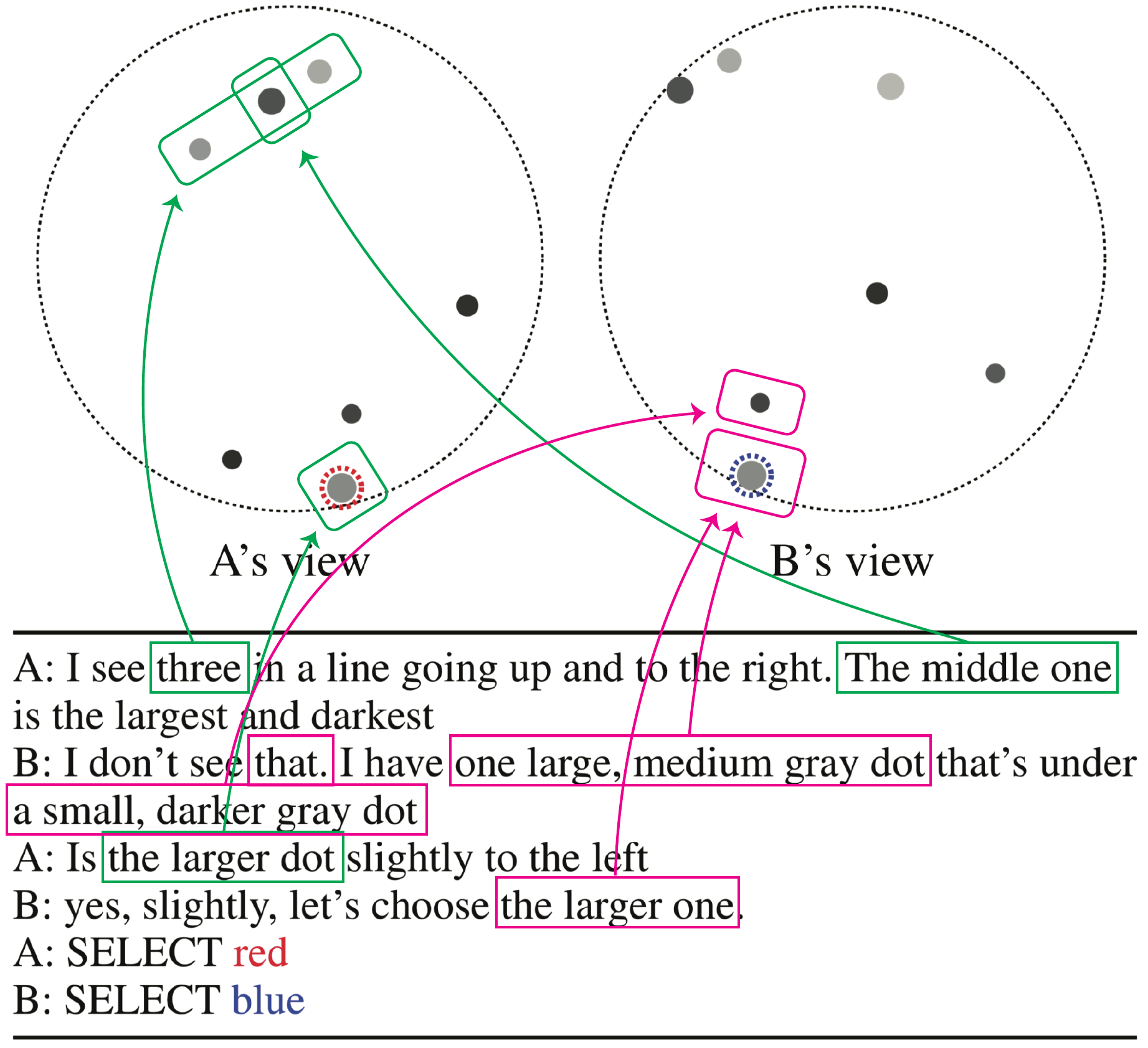
Common grounding is the process of creating, repairing and updating mutual understandings, which is a critical aspect of sophisticated human communication. However, traditional dialogue systems have limited capability of establishing common ground, and we also lack task formulations which introduce natural difficulty in terms of common grounding while enabling easy evaluation and analysis of complex models. In this work, we propose a minimal dialogue task which requires advanced skills of common grounding under continuous and partially-observable context. Based on this task formulation, we collected a large-scale dataset of 6,760 human dialogues, along with the annotations of reference resolution and spatial expressions. Our analyses of the dataset revealed important phenomena related to common grounding that need to be considered. Finally, we evaluate and analyze baseline neural dialogue models on our dataset. We show that they perform decently but leave substantial room left for improvement. Overall, we show that our proposed task will be a fundamental testbed where we can develop, evaluate, and analyze dialogue system’s ability for sophisticated common grounding.(Udagawa and Aizawa: AAAI 2019, Udagawa and Aizawa: AAAI 2020, Udagawa et al.: EMNLP 2020 Findings, dataset)