A formula is mathematical notation used in diverse scenarios of science and education, and plays an important role in various scientific disciplines. However, because a formula is a nonverbal expression, it has been examined only slightly to date as a research subject in natural language processing. We regard a formula not as a kind of image or symbol string but as a component of a document carrying a special structure and interpretation, and analyze a formula associating its description to study of a language processing approach for handling the semantics of a formula. Our research goal is the implementation of an application base of mathematical knowledge through mathematical knowledge search and development and evaluation of an understanding support system using these component technologies.
Construction of a dataset for the evaluation of mathematics information access
We manage a mathematical search task NTCIR-Math under the conference on testbeds for information access research NII Testbeds and Community for Information access Research (NTCIR) to promote dataset construction. We are also constructing a special dataset for formula reference descriptions and formula inclusive relations in papers. Visit the following sites for additional details. (Collaborator: NTCIR Math Organizers)
- NTCIR10 Math Pilot Task
- NTCIR11 Math-2
- NTCIR12 MathIR
- Math Description Annotation for ACL (includes sample 10 full papers)
Extraction of Formulae from Lines

Detecting In-line Mathematical Expressions in Scientific Documents
Unlike an equation that forms an independent line, an “in-line formula” such as a variable that appears in the middle of a line is not necessarily discriminated distinctly from other words, for example, when distinguishing emphasis character A from mathematical symbol A. It is necessary to consider its context of usage to distinguish an in-line formula correctly. We propose through this study a method of extracting in-line formulae precisely considering the visual characteristics such as a font, the linguistic characteristics of surrounding text, and the dependency between formulae over the whole document. This information enables us to extract descriptions of variable definition from PDF documents and other resources easily. (Iwatsuki, Sagara, Hara, Aizawa: DocEng-2017 short [link])
Extraction of natural language explanatory description that refers to a formula
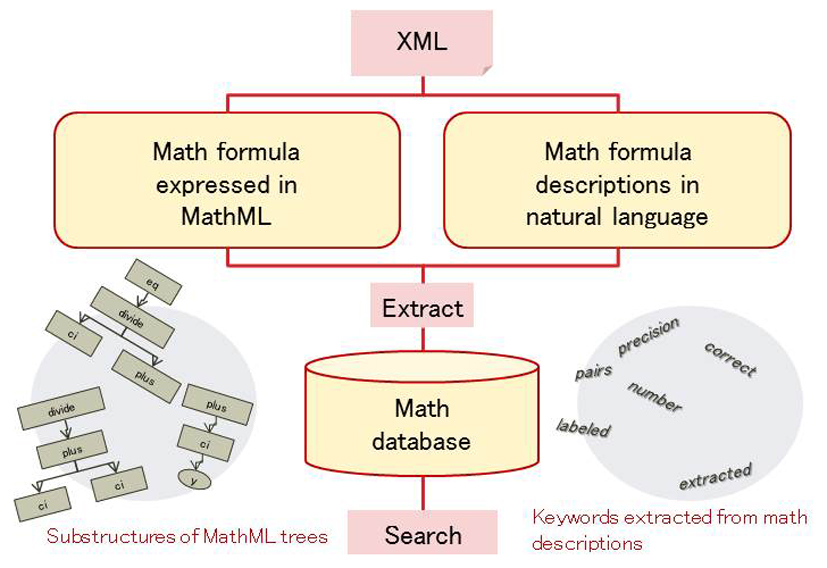
Math formula search system
A formula can be searched easily using existing search engine tools if it is replaced by the ensemble of simple keywords. However, formulae appearing in scientific papers are in such an abstract expression with a complicated structure that they might carry no effective keywords as a clue. Accordingly, we have been developing a procedure to improve the performance of mathematical search based on keywords, automatically extracting the explanatory description of a target formula or the inclusive relation between formulae using manual annotation and the machine-learning method. This technology, which comprehensively analyzes a formula and a natural language text, is effective not only in search but automated acquisition of mathematical knowledge. Furthermore, this method is expected to be related to the integrating process of non-language elements in a document and language texts. (Giovanni Yoko Kristianto)
Construction of an understanding support environment of scientific papers containing formulae
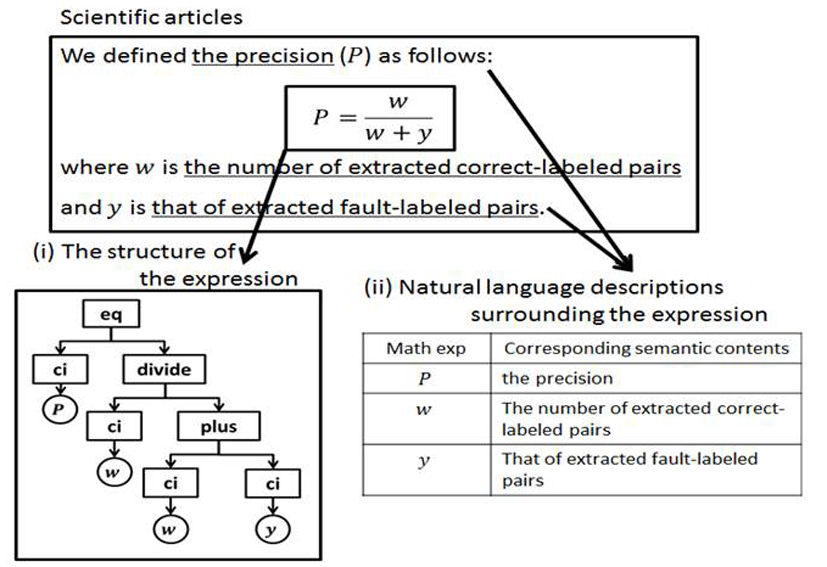
Automatic generation of math formula summary sheet (by Keisuke Yokoi)
We study a method to generate an abstract sheet called Mathsheet automatically for each formula that appears in a paper to assist understanding of the formula. This method permits us to extract the identifiers of variables and functions used in formulae from the description and display them on a pop-up window, and to search for similar formulae in the same paper, other papers, or external formula databases, and display them on a sub-window so that the formula readability can be improved. Because an actual document includes large amounts of missing and variable information, a great challenge for knowledge acquisition is the generation of a Mathsheet automatically. We aim at the automated generation of a Mathsheet considering consistency in a document, using natural language processing technology for the extraction of the identifiers of variables and functions, and using the similarity search technology of a formula tree structure to search for similar formulae. We are constructing and evaluating a demonstration system using mathematics and physics papers, textbooks and papers in information processing, and Wikipedia articles that include formulae. (Giovanni Yoko Kristianto, Goran Topić, and Keisuke Yokoi)
Enhancement of similarity search function for a formula tree structure

SIGRE-hash : an algorithm for alpha equivalence similarity measure (by Shunsuke Ohashi).
It is occasionally necessary to carry out a real-time search from tens of millions of formulae considering partial matching and variable matching to realize a formula search system. We propose a novel similarity calculation algorithm to a formula expressed in the form of an XML tree structure. For example, SIGRE hash is a high-speed similarity calculation algorithm that can accommodate formula queries including variables. Such a device enables us to search a large-scale formula database quickly and flexibly. (Shunsuke Ohashi)
Semantic and structural analysis of formulae by machine translation
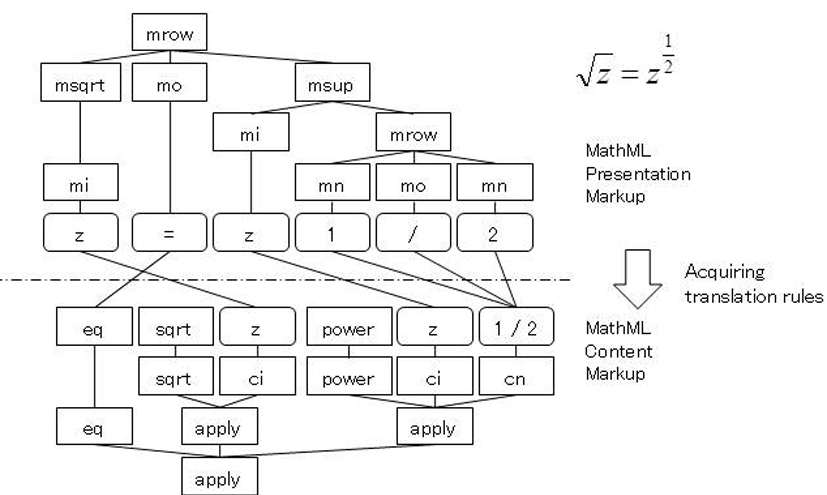
Semantic parsing of presentation-based math expressions (by Nghiêm Quốc Minh).
MathML is a descriptive language for formulae under normalization act by W3C. MathML includes two types: Presentation Markup, which determines the display method on a Web browser; and Content Markup, which shows the semantics and structure of a formula. Although the latter is suitable for formula manipulation by a computer, most formulas converted to XML are expressed in Presentation Markup. Accordingly, we propose a method of acquiring Content Markup from Presentation Markup using machine translation. (Nghiem Quốc Minh)