人間とコンピュータが言語テキストを介してコミュニケーションをとるためには、与えられたテキストに対する理解(解釈)を共有する必要があります。 本研究では、対話システムや言語の基盤化(grounding)の課題に取り組みます。
Evaluating Quality of a Dialogue Response
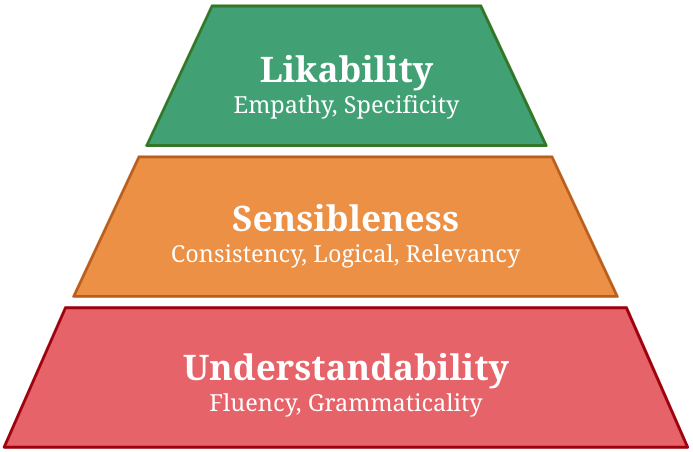
Decomposition the structure ofa response quality
Evaluating natural language is a challenging task. Without a proper assessment of a text’s quality, it is difficult to determine which models can produce a better generation. In this research, we focus on techniques to enhance the evaluation of NLG.
Many automatic evaluation metrics have been proposed to score the overall quality of a response in open-domain dialogue. Generally, the overall quality is comprised of various aspects, such as relevancy, specificity, and empathy, and the importance of each aspect differs according to the task. For instance, specificity is mandatory in a food-ordering dialogue task, whereas fluency is preferred in a language-teaching dialogue system. However, existing metrics are not designed to cope with such flexibility. For example, BLEU score fundamentally relies only on word overlapping, whereas BERTScore relies on semantic similarity between reference and candidate response. Thus, they are not guaranteed to capture the required aspects, i.e., specificity. To design a metric that is flexible to a task, we first propose making these qualities manageable by grouping them into three groups: understandability, sensibleness, and likability, where likability is a combination of qualities that are essential for a task. We also propose a simple method to composite metrics of each aspect to obtain a single metric called USL-H, which stands for Understandability, Sensibleness, and Likability in Hierarchy. We demonstrated that USL-H score achieves good correlations with human judgment and maintains its configurability towards different aspects and metrics. [ Vitou Phy et al.: COLING-2020 , https://github.com/vitouphy/usl_dialogue_metric ]
動的な環境における共通基盤の維持
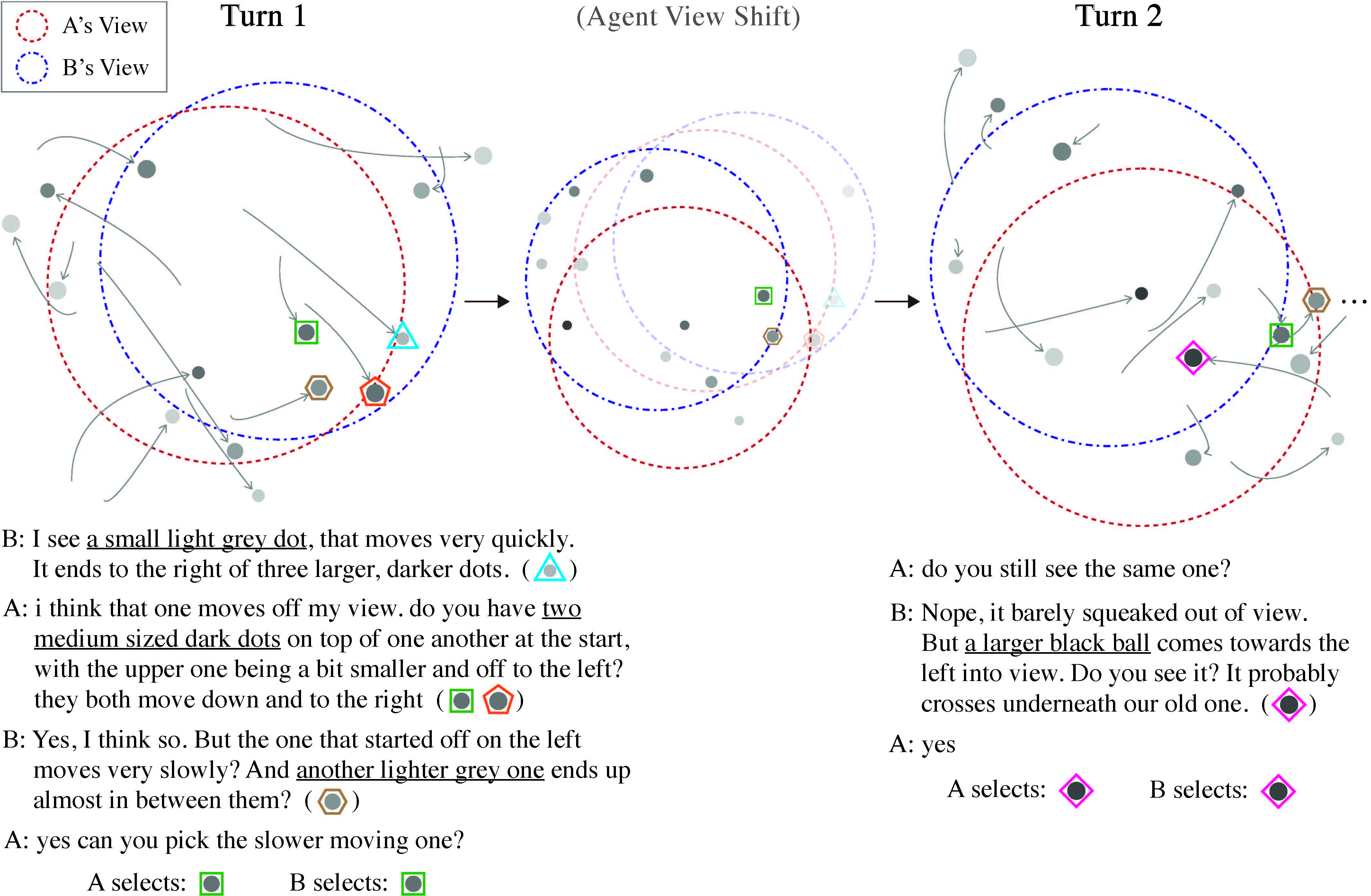
自然言語対話における基盤化とは、話者間で共通理解(共通基盤)を形成・維持する一連のプロセスを指し、人間の高度なコミュニケーションの重要な側面と考えられています。しかし、既存の対話タスクは画像などの静的な情報を扱うものに限られており、動的な環境における共通基盤の形成・維持が十分に考慮されていません。本研究では、既存の基盤化タスク(OneCommon Corpus)を時系列的に拡張し、動的な環境における基盤化を評価する新たなタスク設計を行います。このタスク設計に基づき、クラウドソーシングを用いて5,617対話を含む大規模なデータセットを新たに構築しました。データセットの分析の結果、提案タスクでは複雑な時空間表現を用いた基盤化が必要であること、また人間同士では過去の時点での共通基盤を利用してより正確かつ効率的に共通基盤の更新・維持ができていることが確認できました。最後に、深層学習に基づく対話モデルを実装し、提案タスクによる評価・分析を行いました。その結果、既存モデルは色・大きさ・位置などの空間的情報は(比較的)利用できているものの、動作・時制などの時間的情報はまだうまく扱えていないことが示唆されました。(Udagawa and Aizawa: TACL 2021, dataset)
連続的かつ部分観測的コンテクストにおける共通基盤の形成
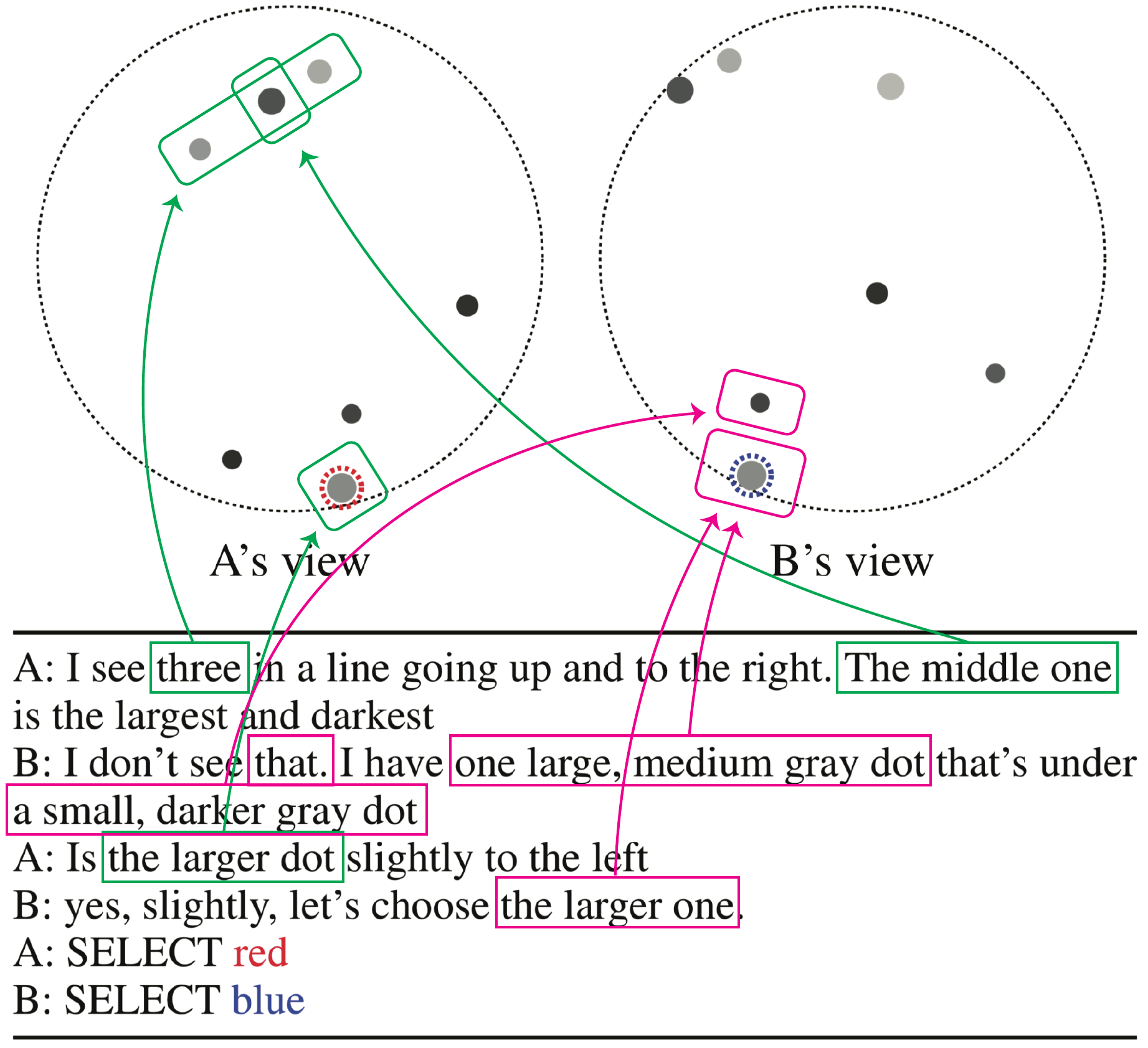
人間は自然言語による対話を通じて様々な共通理解を作り出し、必要に応じて修正・維持することができます。本研究では、このような人間の高度なコミュニケーション能力に焦点を当てたタスクの設計と対話システムの評価・分析を行います。具体的には、連続的かつ部分観測的な情報について共通理解を形成する新しい対話タスクを定義し、6,760対話を含む大規模なデータセットを構築しました。また、参照表現・空間表現のアノテーションを通じて、基盤化のプロセスの詳細な分析ができるようになっています。最後に、深層学習に基づくベースラインモデルはある程度の性能を出せるものの、高度な基盤化を実現するには改善の余地が大きく残ることを示します。(Udagawa and Aizawa: AAAI 2019, Udagawa and Aizawa: AAAI 2020, Udagawa et al.: EMNLP 2020 Findings, dataset)