[:en]A formula is mathematical notation used in diverse scenarios of science and education, and plays an important role in various scientific disciplines. However, because a formula is a nonverbal expression, it has been examined only slightly to date as a research subject in natural language processing. We regard a formula not as a kind of image or symbol string but as a component of a document carrying a special structure and interpretation, and analyze a formula associating its description to study of a language processing approach for handling the semantics of a formula. Our research goal is the implementation of an application base of mathematical knowledge through mathematical knowledge search and development and evaluation of an understanding support system using these component technologies.
Construction of a dataset for the evaluation of mathematics information access
We manage a mathematical search task NTCIR-Math under the conference on testbeds for information access research NII Testbeds and Community for Information access Research (NTCIR) to promote dataset construction. We are also constructing a special dataset for formula reference descriptions and formula inclusive relations in papers. Visit the following sites for additional details. (Collaborator: NTCIR Math Organizers)
- NTCIR10 Math Pilot Task
- NTCIR11 Math-2
- NTCIR12 MathIR
- Math Description Annotation for ACL (includes sample 10 full papers)
Extraction of Formulae from Lines

Unlike an equation that forms an independent line, an “in-line formula” such as a variable that appears in the middle of a line is not necessarily discriminated distinctly from other words, for example, when distinguishing emphasis character A from mathematical symbol A. It is necessary to consider its context of usage to distinguish an in-line formula correctly. We propose through this study a method of extracting in-line formulae precisely considering the visual characteristics such as a font, the linguistic characteristics of surrounding text, and the dependency between formulae over the whole document. This information enables us to extract descriptions of variable definition from PDF documents and other resources easily. (Iwatsuki, Sagara, Hara, Aizawa: DocEng-2017 short [link])
Extraction of natural language explanatory description that refers to a formula
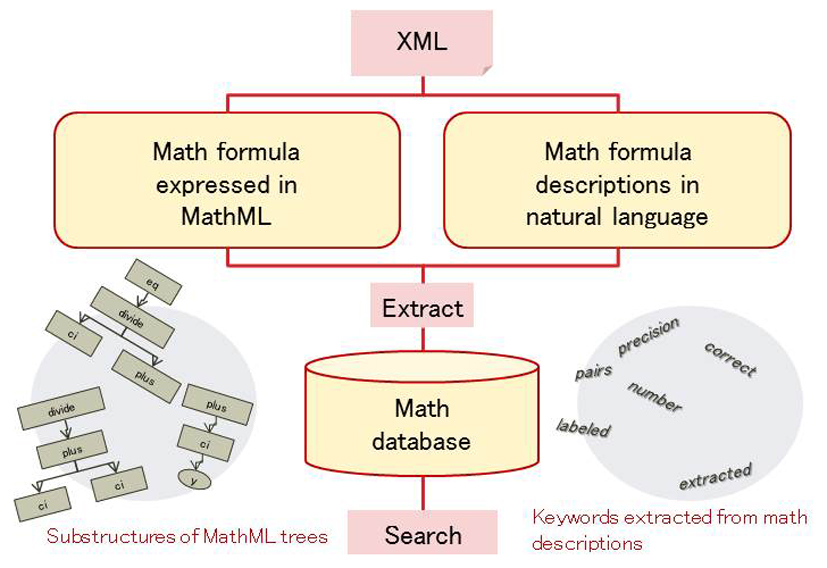
A formula can be searched easily using existing search engine tools if it is replaced by the ensemble of simple keywords. However, formulae appearing in scientific papers are in such an abstract expression with a complicated structure that they might carry no effective keywords as a clue. Accordingly, we have been developing a procedure to improve the performance of mathematical search based on keywords, automatically extracting the explanatory description of a target formula or the inclusive relation between formulae using manual annotation and the machine-learning method. This technology, which comprehensively analyzes a formula and a natural language text, is effective not only in search but automated acquisition of mathematical knowledge. Furthermore, this method is expected to be related to the integrating process of non-language elements in a document and language texts. (Giovanni Yoko Kristianto)
Construction of an understanding support environment of scientific papers containing formulae
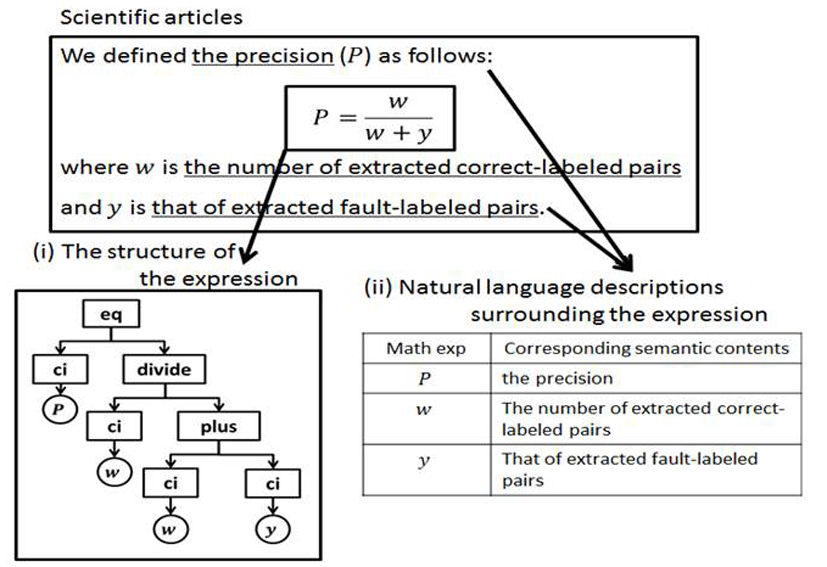
We study a method to generate an abstract sheet called Mathsheet automatically for each formula that appears in a paper to assist understanding of the formula. This method permits us to extract the identifiers of variables and functions used in formulae from the description and display them on a pop-up window, and to search for similar formulae in the same paper, other papers, or external formula databases, and display them on a sub-window so that the formula readability can be improved. Because an actual document includes large amounts of missing and variable information, a great challenge for knowledge acquisition is the generation of a Mathsheet automatically. We aim at the automated generation of a Mathsheet considering consistency in a document, using natural language processing technology for the extraction of the identifiers of variables and functions, and using the similarity search technology of a formula tree structure to search for similar formulae. We are constructing and evaluating a demonstration system using mathematics and physics papers, textbooks and papers in information processing, and Wikipedia articles that include formulae. (Giovanni Yoko Kristianto, Goran Topić, and Keisuke Yokoi)
Enhancement of similarity search function for a formula tree structure

It is occasionally necessary to carry out a real-time search from tens of millions of formulae considering partial matching and variable matching to realize a formula search system. We propose a novel similarity calculation algorithm to a formula expressed in the form of an XML tree structure. For example, SIGRE hash is a high-speed similarity calculation algorithm that can accommodate formula queries including variables. Such a device enables us to search a large-scale formula database quickly and flexibly. (Shunsuke Ohashi)
Semantic and structural analysis of formulae by machine translation
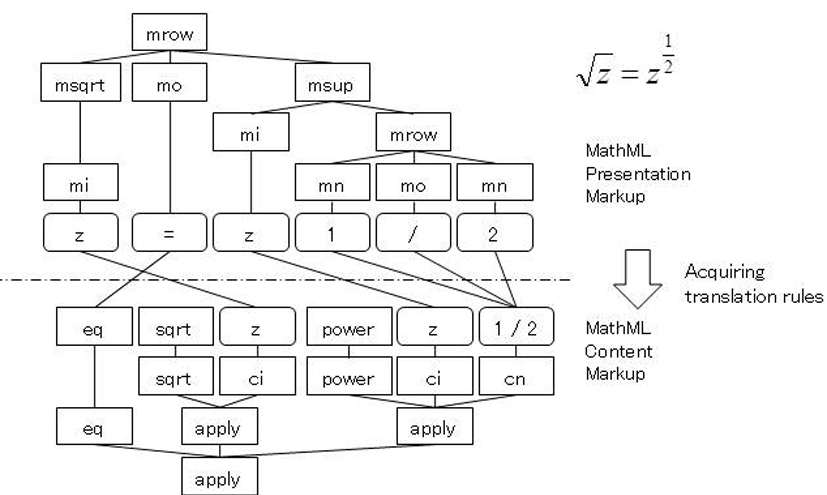
MathML is a descriptive language for formulae under normalization act by W3C. MathML includes two types: Presentation Markup, which determines the display method on a Web browser; and Content Markup, which shows the semantics and structure of a formula. Although the latter is suitable for formula manipulation by a computer, most formulas converted to XML are expressed in Presentation Markup. Accordingly, we propose a method of acquiring Content Markup from Presentation Markup using machine translation. (Nghiem Quốc Minh)
[:ja]数式は、科学・教育のさまざまな場面で使われる数学の記述法で、多くの科学分野で重要な役割を果たします。しかし数式は非言語的な表現であることから、自然言語処理の研究対象として考慮されることは、これまでほとんどありませんでした。これに対して本研究では、数式を画像や記号列の一種ではなく、独自の構造と解釈を持つ文書の構成要素として捉え、数式とその説明文を対応付けて解析することで、数式の意味を扱うための言語処理アプローチについて研究しています。また、これらの要素技術を用いた数学的知識の検索や理解支援システムの開発や評価を通して、数学的知識の活用基盤の実現に取り組んでいます。
数学情報アクセスの評価用データセットの構築
情報アクセス研究の評価用基盤構築カンファレンス NTCIR (NII Testbeds and Community for Information access Research)のもとで数式検索タスク NTCIR-Mathを運営し、データセットの構築を進めています。また、論文中の数式参照記述や数式包含関係について独自のデータセットを構築しています。詳しくは以下のサイトをご覧下さい。(共同研究者:NTCIR Math Organizers)
- NTCIR10 Math Pilot Task
- NTCIR11 Math-2
- NTCIR12 MathIR
- Math Description Annotation for ACL (includes sample 10 full papers)
行内数式の抽出
独立行数式と異なり、行内に出現する変数などの「数式」は必ずしも他の語と明確に区別されているわけではありません。たとえば、強調文字としての A と数学記号の A を区別する場合などです。行内数式を正しく認識するためには、その出現文脈を考慮することが必要になります。そこで本研究では、フォントなどの視覚的特徴、周辺テキストの言語的特徴、文書全体の中での数式の依存関係などを考慮して、行内数式を精度よく抽出する手法を提案しました。これによってPDF文書からの変数定義記述の抽出などが容易になります。(Iwatsuki, Sagara, Hara, Aizawa: DocEng-2017 short [link])
数式を参照する自然言語説明記述の抽出
数式を単純なキーワードの集合に置き換えることができれば、既存の検索エンジンツールを使って簡単に数式の検索を実現することができます。しかし、科学技術論文中に出現する数式は複雑な構造を持つ抽象的な表現であり、手がかりとして有効なキーワードが含まていないことも多くあります。そこで本研究では、人手によるアノテーションと機械学習手法を用いて、検索対象となる数式の説明記述や数式間の包含関係を自動抽出して、キーワードに基づく数式検索の性能を高める手法の開発に取り組んでいます。このような技術は、数式と自然言語テキストをあわせて解析するもので、検索だけではなく数学的知識の自動獲得にも有効です。さらには、文書中の非言語要素と言語テキストの統合処理へと結びつくことが期待されます。(Giovanni Yoko Kristianto)
数式を含む論文の理解支援環境の構築
論文中に書かれた数式の理解を支援するため、論文中に出現する個々の数式に対して、Mathsheetと呼ぶ要約シートの自動生成を行う手法を研究しています。これによって、説明文から数式で使われている変数や関数の名前を抽出してポップアップで表示したり、同一論文中や他の論文や外部の数式データベース上の類似数式を捜してサブウィンドウに表示したりすることが可能になり、数式の可読性を高めることができます。現実の文書は情報の欠落や揺らぎ等を多く含むため、このような要約シートを自動的に生成することは知識獲得の大きなチャレンジ課題です。本研究では、変数や関数の名前の抽出には自然言語処理の技術を、類似数式の検索には数式木構造の類似検索技術を使い、文書内での一貫性に考慮した要約シートの自動生成を目指しています。数学や物理学分野の論文、情報処理分野の論文、教科書、数式を含むWikipedia記事などを対象に、デモシステムの構築や評価に取り組んでいます。(Giovanni Yoko Kristianto、Goran Topić、横井啓介)
数式木構造の類似検索検索機能の強化
数式検索システムの実現にあたっては、ときには数千万個の数式に対して、部分一致や変数マッチングを考慮してリアルタイム検索を行うことが必要になります。そこで本研究では、XML木構造の形で表された数式に対する新しい類似度計算アルゴリズムを提案しています。たとえば SIGREハッシュと呼ぶ手法は、変数を含む数式クエリを扱うことができる高速な類似度計算アルゴリズムです。このような工夫によって、大規模な数式データベースを高速かつ柔軟に検索することが可能になります。(大橋駿介)
機械翻訳手法の適用による数式の意味構造解析
数式の記述言語とし、W3Cが標準化をすすめるMathMLがあります。MathMLには、Webブラウザ上での表示方法を定めるPresentation Markup と数式の意味構造を示すためのContent Markupの2通りがあります。後者のContent Markupは、計算機による数式処理との相性がよい言語ですが、現状ではXML化された数式の大半はPresentation Markupで表現されています。そこで本研究では機械翻訳の手法を用いて、Presentation Markup からContent Markupを獲得する手法を提案しています。(Nghiêm Quốc Minh)
[:]