Hajime Senuma
Tree-Walking on Myriad Leaves
Walking on tree structures is one of the most fundamental operations both in computer science and in linguistics. In practice, tree traversal is a key technique in programming; in theory, many important problems such as non-projective dependency parsing (that is, analysis of complex sentences) are reducible to the problem of tree-walking automata (TWA). To handle this crucial class of computational power, we are working on the following issues: 1. deep learning of neural TWA and its application to natural language processing, 2. succinct and scalable representation of walkable tree structures, and 3. annotation of morpho-syntactically complex languages.
Zhao Yang
Neural network-based summarization system
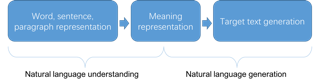
Summarization systems aim to produce a shorter version of a source text by preserving the meaning and the key contents of the original. I am working on summarization, especially, the abstractive summarization which generally speaking consists of original text representation, meaning representation as well as summary text generation. With the development of neural network techniques in summarization, encouraging results are yielded. My current work and interest involve incorporating knowledge into neural network-based summarization system with gating mechanism we proposed. Also, we put the effort in yielding better meaning and generation representation of text in abstractive summarization by employing deep learning techniques.
Saku Sugawara
Evaluation Methodology for Machine Reading Comprehension Task: Prerequisite Skills and Readability
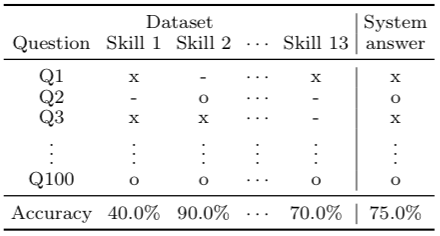
A major goal of natural language processing (NLP) is to develop agents that can understand natural language. Such an ability can be tested with a reading comprehension (RC) task that requires the agent to read open-domain documents and answer questions about them. In this situation, knowing the quality of reading comprehension (RC) datasets is important for the development of natural language understanding systems. We adopted two classes of metrics for evaluating RC datasets: prerequisite skills and readability. We applied these classes to six existing datasets, including MCTest and SQuAD, and demonstrated the characteristics of the datasets according to each metric and the correlation between the two classes. Our dataset analysis suggested that the readability of RC datasets does not directly affect the question difficulty and that it is possible to create an RC dataset that is easy-to-read but difficult-to-answer.
Kenichi Iwatsuki
Writing Assistance for Non-native English speakers with Formulaic Languages
Systems for writing assistance have been implemented in natural language processing community, and most of them are focused on searching for or suggesting English expressions. However, what is required to help non-native speakers write an English paper has been paid little attention to. Moreover, since machine translation technologies has developed drastically, we no longer need to tackle problems that fundamentally translation can solve.
In applied linguistics and pedagogy (especially second language acquisition, or English for specific purposes) formulaic language has been said to be useful to help us write. They tried extracting formulaic languages in corpus, but we need to consider what is formulaic language in the first place so that computers can address ones.
Currently, I am being focused on computational expression or definition of formulaic languages.
Takuma Udagawa
Deep Reinforcement Learning and Applications in NLP
Recently there has been a surge of interest in applying deep learning to reinforcement learning problems. My research goal is to enhance the possibility of deep reinforcement learning algorithms and its applications to various NLP tasks, including language acquisition, dialogue systems, and much more.
Vitor Castro
Computational argumentation for automatic scoring of argumentative essays
Computational argumentation is a relatively new challenge in the field of natural language processing. It consists in automatically analyzing the argumentative structure of texts, including the relationships between pairs of articles, in various fields, from online debates and product reviews to legal documents and scientific articles. In this work, we plan to utilize and improve on techniques in this field in order to tackle the specific task of automatic scoring of argumentative essays, especially for foreign language learners, and utilize the argumentative structure obtained from this process to aid the student’s learning process. With end-user visualization and summarization of arguments, we hope it is possible for the student to understand the points of the essay that need improvement and why the argumentation is weak at those points.
Akira Moroo
Crash Report Deduplication
A crash report is an information when the software is unexpectedly terminated.
It is composed of a plurality of information, stack trace among them is the most important to fix bugs because they store the calling sequence of functions.
Software projects often collect crash reports from the users.
However, a huge amount of crashes is reported, and the are often duplicated.
Therefore, it is necessary to cluster the crashes automatically by each bug.
Most of the automated crash report clustering methods have a problem that they can not deduplicate a massive amount of reports in real time due to the calculation complexity.
On the other hand, there is a problem that the accuracy is low in the method using the full-text search engine in order to deal with this problem.
I am trying to eliminate above trade-off by applying techniques of information retrieval, aiming at high speed and high accuracy clustering.
Vincent Stange
CitePlag
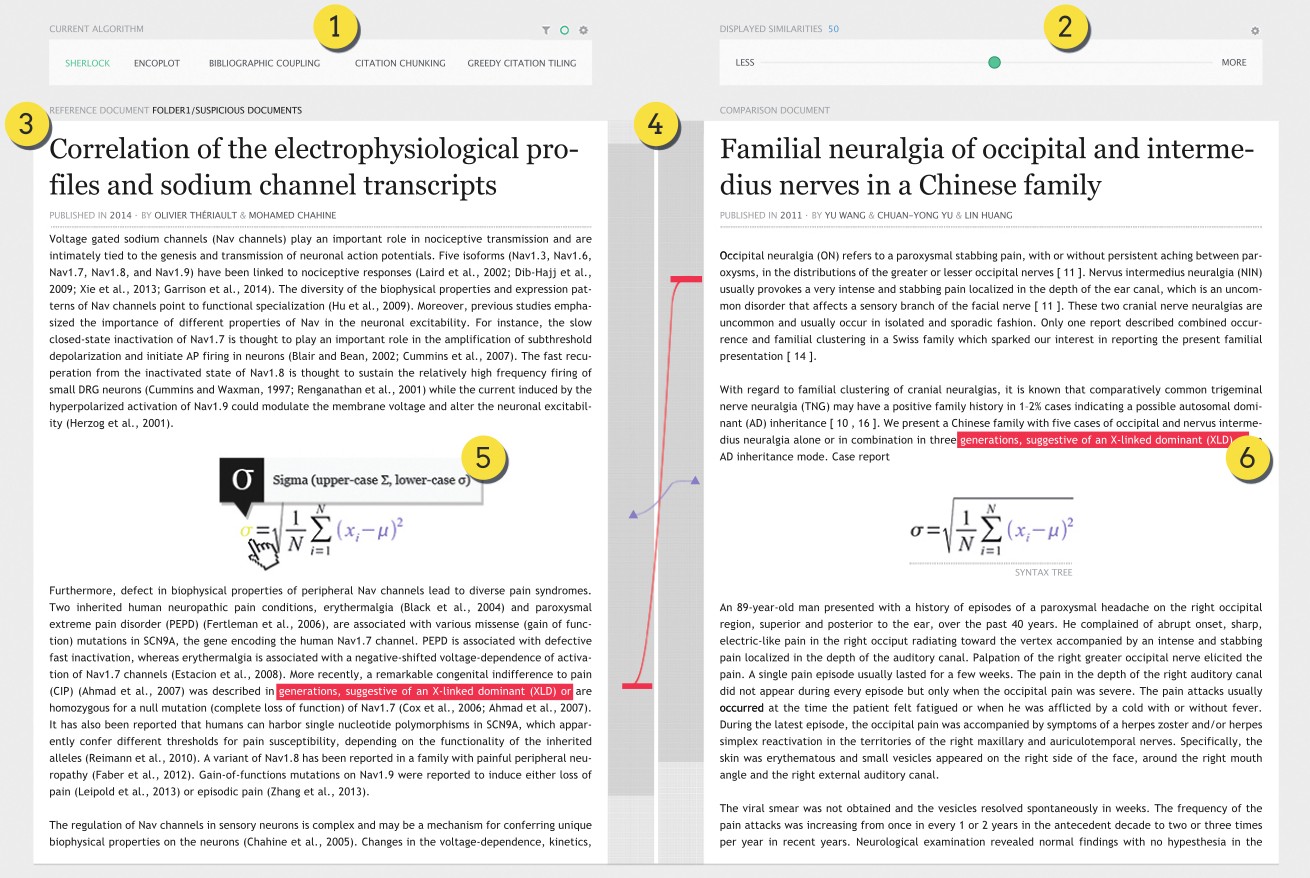
CitePlag is a prototype of a hybrid Plagiarism Prevention and Detection System developed by the Information Science Group at the University of Konstanz in Germany. Compared to existing approaches for plagiarism detection, the CitePlag prototype does not consider textual similarity alone, but uses citation patterns within academic documents as a unique, language-independent fingerprint to identify semantic similarity.
In cooperation with the National Institute of Informatics in Tokyo the current research approaches the identification for similarities of mathematical formulas and images. Thus CitePlag will be the first Citation and Formula based Plagiarism Detection System – a novel approach capable of detecting also heavily disguised plagiarism forms, including paraphrases, translated plagiarism, and even idea plagiarism in academic texts.