Development of information technology has enabled us to process a huge quantity of language texts using a computer. However, fundamental information is not necessarily expressed in a text in a favorable fashion. Knowledge embedded into a text only becomes available through the understanding of its reader. Consequently, it is a great challenge for artificial intelligence to comprehend the fundamental function of human intelligence in which knowledge is transformed, combined, and used. We are conducting research on knowledge acquisition using language analysis by a computer and application of knowledge acquired, to undertake a more fundamental task: search for a widespread knowledge space generated by operations such as generalization, integration, and inference.
Combining fragmented knowledge: Text linking technology and its application
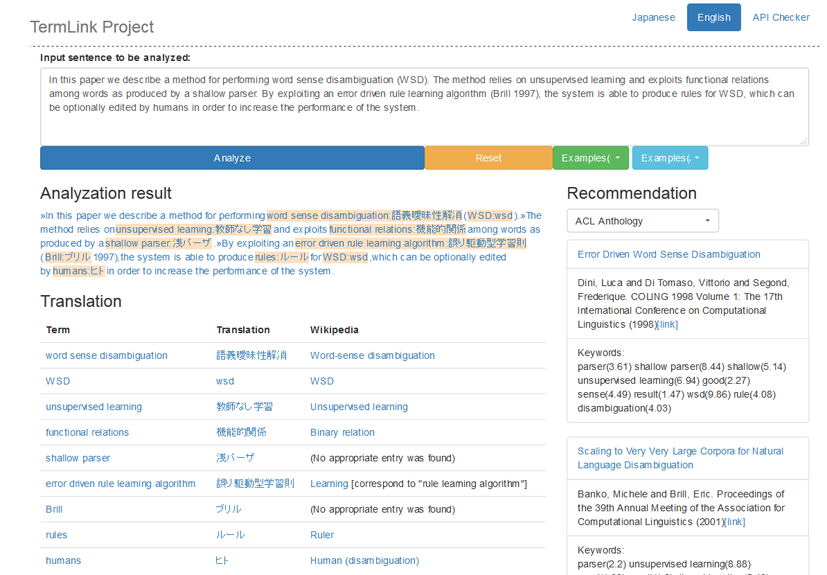
TermLink server demo
Knowledge processing by AI is demanded acutely in modern information societies to use a huge amount of contents produced and accumulated daily. Language processing technology, which carries out automated knowledge acquisition from a text, serves as the core. Especially “entity linking,” which connects the concept and identifier of things in a text to external knowledge, is attracting attention lately as an indispensable technology for knowledge acquisition. However, most present linking systems assume intrinsic expressions such as a person’s name, but they do not deal with abstract concepts that are useful for the systematization of knowledge. Accordingly, we specifically examine “technical terms” by which each domain is characterized, and study the regularization of terms, lexical resource compilation, term translation, and dissolution technology of equivocation for connecting a technical term to external knowledge sources. We have constructed a demonstration system as an example of knowledge processing by linking, which has a linking server for scientific documents and which performs reference recommendation from Japanese to English and extraction of links to related Wikipedia articles. Because concepts identified by linking constitute a base unit of information acquisition or knowledge inference, they are expected to be applied for discovery of knowledge across languages and domains and for the integration of knowledge bases.
Recommendation of relevant information adapted to the structure of a paper and the browsing support system
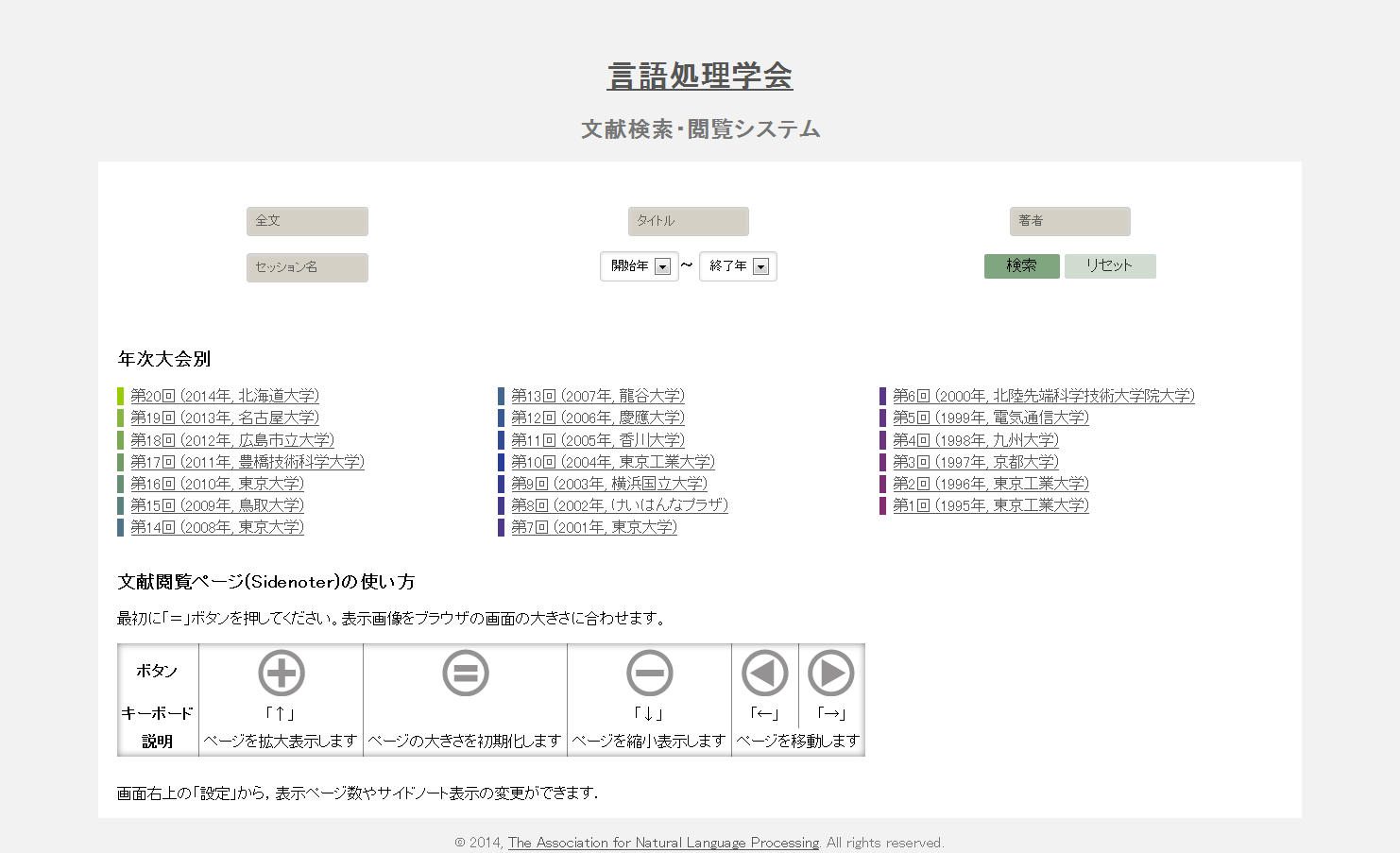
SideNoter demo site.
We study the information recommendation method, which presents useful relevant information and articles related to knowledge bases in accordance with logical structures such as sections and paragraphs of a document. We are also developing and operating SideNoter, a PDF browsing system with annotations for scientific papers in cooperation with Dr. Takeshi Abekawa of NII. SideNoter displays recommendation information automatically by the side of a page as an annotation. We operate a demonstration site using the Archive of Proceedings for NLP Annual Meeting that is currently open to public by the Association for Natural Language Processing of Japan. Implementation of SideNoter requires diverse technologies such as the structure analyses of PDF documents, term linking, identification of references, and multilanguage paper recommendation so that the application of SideNoter is anticipated as the demonstration base of the logical, semantic, and structural analytic method of papers containing these. (Collaborators: Takeshi Abekawa and Takeshi Sagara)
Extraction of natural language sentences from structurized documents
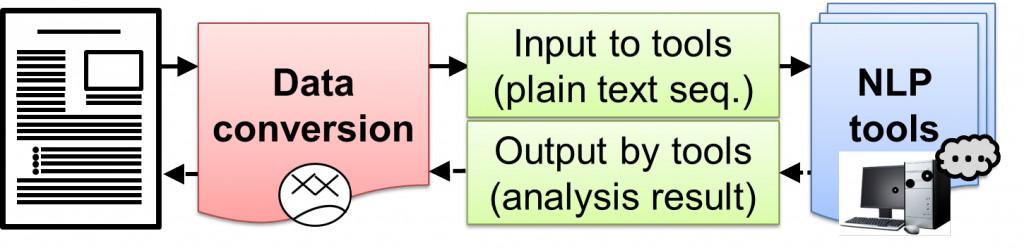
Converting XML document into plain text based on tag classification
Most natural language processing tools premise a “sentence” as an input. However, many actual documents as analytical objects carry various structural information embedded in the text, such as a title and notes, so that existing natural language tools are inapplicable. We propose a framework for supporting an objective to “analyze documents of the real world containing structurized texts with natural language processing (NLP) tools in hand” in this project, and mounted a converting tool PlaneText. Its latest version can convert an XML-tagged text to a sentence that is directly accepted by an NLP tool. This approach not only enhances the quality of a “sentence” extracted from a document but improves the efficiency of syntactic analysis. (Tadayoshi Hara and Goran Topić)
Paper recommendation in which relevant papers are presented from diverse viewpoints
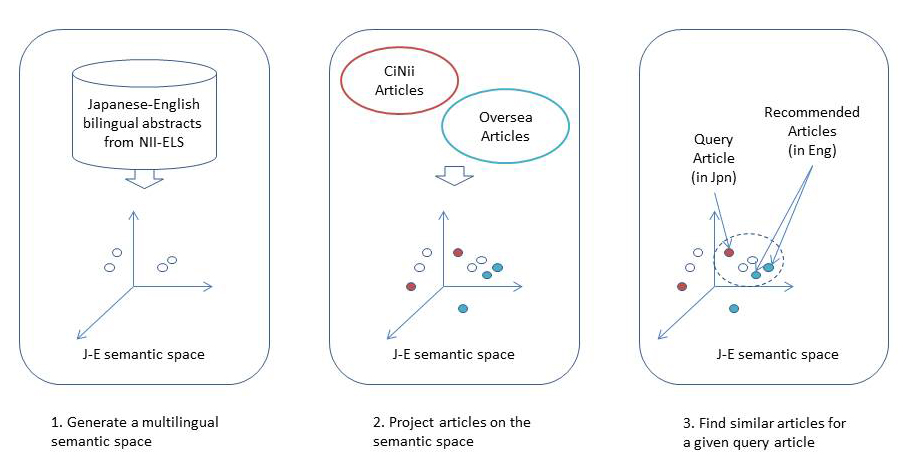
Cross-lingual scientific paper recommendation using LDA
We constructed a recommendation system that enables us to conduct a paper search based on diverse viewpoints such as “popularity degree” or “discipline dissimilarity.” Relevant papers to the given paper are nominated. Then they are graded based on various viewpoints by multiple recommenders. Finally they are presented to the user in this system. We have mounted many advanced features as follows experimentally: (1) personalization feature to extract keywords from papers of the user’s own in the past, and to recommend papers of high relevance using them preferentially; (2) multilanguage recommendation feature to recommend the latest papers of domestic and overseas from the search results of Japanese papers; (3) semantics and role assignment feature to classify technical terms used in a paper and present them whether they are the objective or the means of the paper; and (4) serendipity recommendation feature to compute the distance between disciplines and to assign priority to papers with high unpredictability. Although the project was completed in 2012, the experience has been inherited to the succeeding project. (Collaborators: Atsuhiro Takasu, Kiyoko Uchiyama, Hidetsugu Namba, and Takeshi Sagara)
Academic linkage: Data integration by identification of scientific articles and researchers
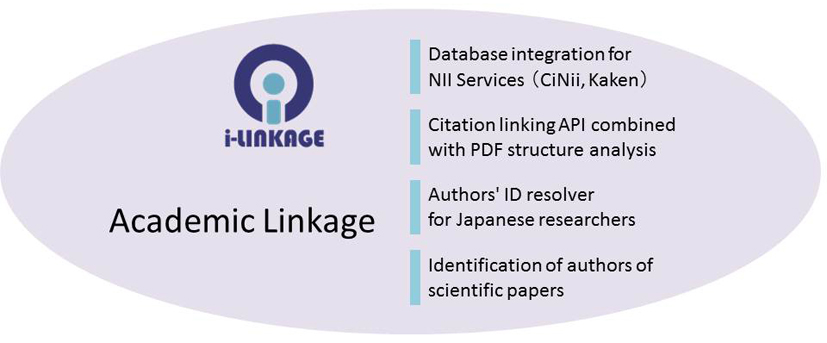
Information linkage engine for advance academic infrastructure.
We have studied a high-speed information linkage technology for associating bibliographic information related to scientific paper databases or book catalogs, and quoted strings extracted from whole papers or websites, and have developed a high-speed bibliographic identification engine i-linkage using suffix arrays and machine learning. We have constructed a researcher identification system that identifies the names of tens of millions of paper authors using this bibliographic identification. This method is a core technology that is indispensable to the advancement of the scholarly information infrastructure. Its importance is broadly recognized. The engine developed in this study has been used for the identification of papers and authors in NII service or in the succeeding project.